GPU Tesla T4 được Nvidia giới thiệu tại hội nghị công nghệ GPU gần đây và sản phẩm sử dụng trong nền tảng TensorRT Hyperscale Inference. Đây cũng một trong số ít nền tảng tốt nhất hiện nay có khả năng khai thác hiệu quả sức mạnh của học máy (machine learning) và trí tuệ nhân tạo (AI).
Đại diện Nvidia cho biết việc ra mắt GPU Tesla T4 nhằm thúc đẩy sự phát triển các dịch vụ trí tuệ nhân tạo (AI) trên toàn thế giới. Theo ước tính, ngành công nghiệp mới mẻ này sẽ thúc đẩy tích cực lĩnh vực thương mại, tiêu dùng và thậm chí phát triển thành một thị trường có giá trị tối thiểu 20 tỷ USD trong 5 năm tới.

Chúng tôi đang hướng đến một tương lai mà ở nơi đó, tất cả sản phẩm, dịch vụ của khách hàng đều được AI tác động và cải tiến để ngày càng tốt hơn. Và nền tảng TensorRT Hyperscale Inference được thiết kế cho điều này. Ông Ian Buck, Phó chủ tịch kiêm Tổng giám đốc mảng Accelerated Business của Nvidia chia sẻ.
Nhờ khả năng cung cấp hiệu suất cao với độ trễ thấp cho các ứng dụng, TensorRT Hyperscale Inference platform giúp các trung tâm dữ liệu mở rộng thêm nhiều dịch vụ mới, chẳng hạn như nâng cao khả năng tương tác của ngôn ngữ tự nhiên, xử lý trực tiếp các truy vấn tìm kiếm của người dùng thay vì dựa trên danh sách kết quả có sẵn.
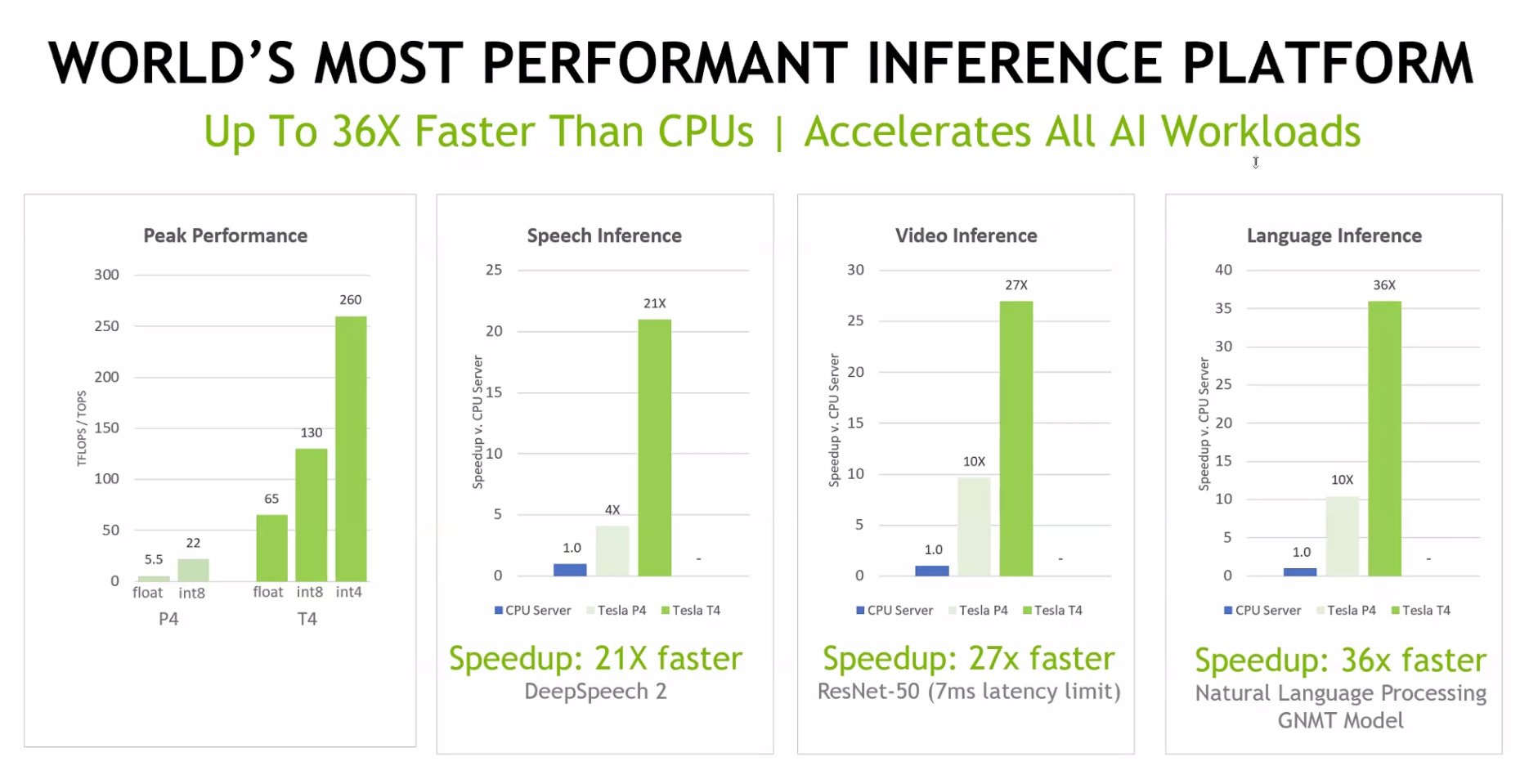
Thông thường, một trung tâm dữ liệu cỡ lớn phải xử lý hàng tỷ truy vấn mỗi ngày dưới các dạng thức khác nhau, từ giọng nói, bản dịch, hình ảnh, video, đề xuất và tương tác trên mạng xã hội. Mỗi ứng dụng nhỏ trong số đó sẽ cần một loại neural network (mạng nơron thần kinh) khác nhau nằm trên máy chủ để xử lý.
Để tối ưu lượng dữ liệu truy xuất và khai thác tối đa sức mạnh của máy chủ, TensorRT Hyperscale Inference Platform sử dụng giải pháp kết hợp cả phần mềm suy luận thời gian thực (real-time inference) lẫn phần cứng với các GPU Tesla T4 nhằm tăng tốc xử lý truy vấn. Vì vậy tốc độ đạt được có thể nhanh hơn 40 lần so với CPU thế hệ tương đương, ông Ian Buck cho biết.
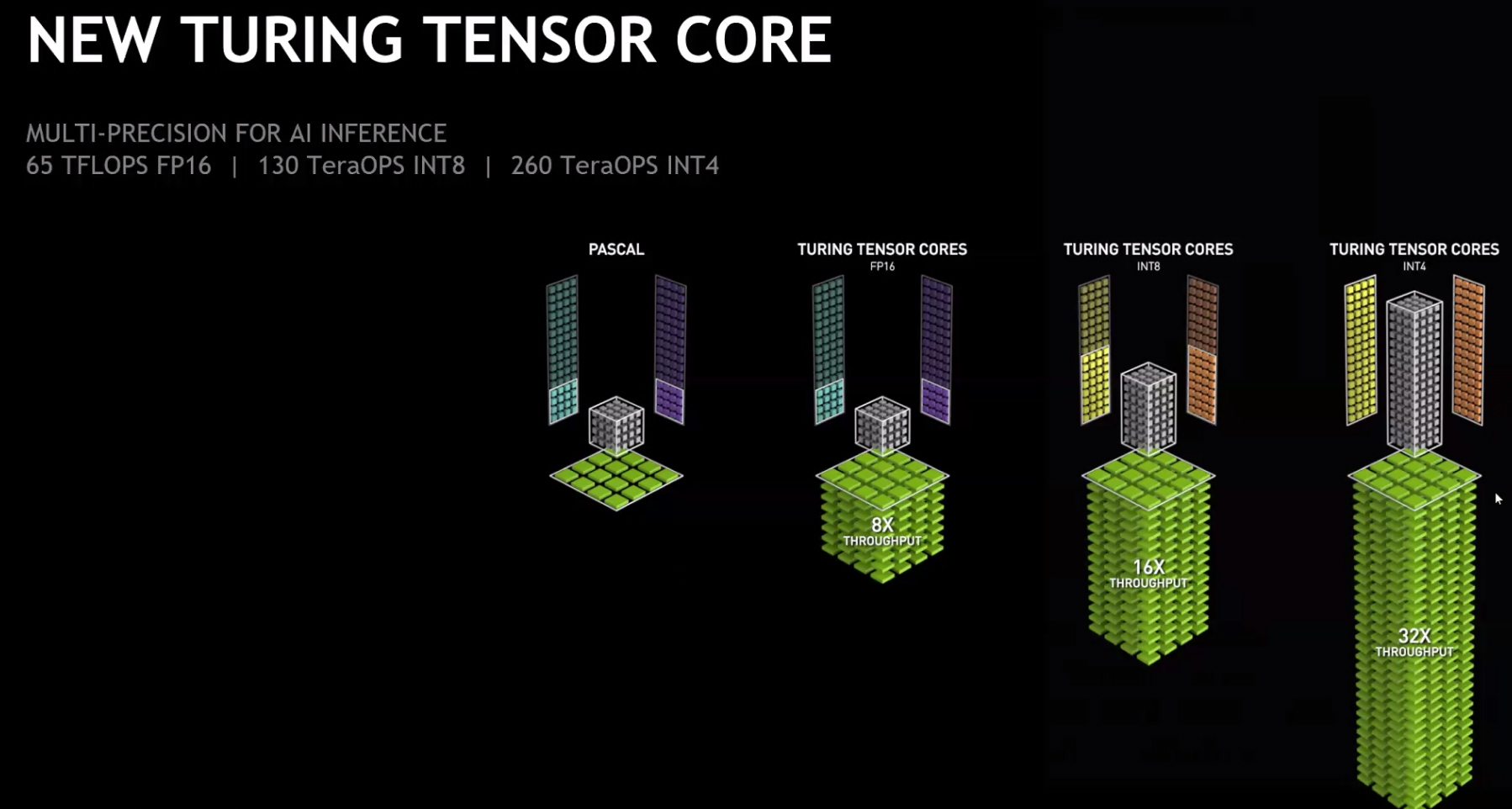
Trở lại với Tesla T4 thì đây là mẫu GPU được Nvidia phát triển dựa trên kiến trúc Turing, tương tự RTX 20 series mà hãng giới thiệu đến người dùng cách đây không lâu. Cụ thể Tesla T4 có tổng cộng 2.560 nhân CUDA, đặc biệt là 320 nhân Tensor mang lại sự đột phá về năng lực xử tính toán dấu chấm động có độ chính xác đơn (FP32), dấu chấm động bán chính xác (FP16), số nguyên 8 bit (INT8) cũng như 4 bit (INT4).
Về kích cỡ, Tesla T4 đóng gói theo dạng card PCI Express với năng lượng tiêu thụ chỉ 75W. Theo thiết kế, mẫu GPU mới của Nvidia chạy cùng TensorRT 5, một engine được tối ưu nhằm hỗ trợ các nhân Tensor, mở rộng thiết lập mạng nơron để đáp ứng những yêu cầu cần độ chính xác bội (multi-precision) của ứng dụng máy học và AI. Bên cạnh đó, TensorRT còn hỗ trợ kiến trúc hướng dịch vụ theo mô hình microservice, đơn giản hóa mọi sự phức tạp để các dịch vụ có thể khai thác AI hiệu quả.
Đại diện Nvidia cho biết việc ra mắt GPU Tesla T4 nhằm thúc đẩy sự phát triển các dịch vụ trí tuệ nhân tạo (AI) trên toàn thế giới. Theo ước tính, ngành công nghiệp mới mẻ này sẽ thúc đẩy tích cực lĩnh vực thương mại, tiêu dùng và thậm chí phát triển thành một thị trường có giá trị tối thiểu 20 tỷ USD trong 5 năm tới.
Chúng tôi đang hướng đến một tương lai mà ở nơi đó, tất cả sản phẩm, dịch vụ của khách hàng đều được AI tác động và cải tiến để ngày càng tốt hơn. Và nền tảng TensorRT Hyperscale Inference được thiết kế cho điều này. Ông Ian Buck, Phó chủ tịch kiêm Tổng giám đốc mảng Accelerated Business của Nvidia chia sẻ.
Nhờ khả năng cung cấp hiệu suất cao với độ trễ thấp cho các ứng dụng, TensorRT Hyperscale Inference platform giúp các trung tâm dữ liệu mở rộng thêm nhiều dịch vụ mới, chẳng hạn như nâng cao khả năng tương tác của ngôn ngữ tự nhiên, xử lý trực tiếp các truy vấn tìm kiếm của người dùng thay vì dựa trên danh sách kết quả có sẵn.
Thông thường, một trung tâm dữ liệu cỡ lớn phải xử lý hàng tỷ truy vấn mỗi ngày dưới các dạng thức khác nhau, từ giọng nói, bản dịch, hình ảnh, video, đề xuất và tương tác trên mạng xã hội. Mỗi ứng dụng nhỏ trong số đó sẽ cần một loại neural network (mạng nơron thần kinh) khác nhau nằm trên máy chủ để xử lý.
Để tối ưu lượng dữ liệu truy xuất và khai thác tối đa sức mạnh của máy chủ, TensorRT Hyperscale Inference Platform sử dụng giải pháp kết hợp cả phần mềm suy luận thời gian thực (real-time inference) lẫn phần cứng với các GPU Tesla T4 nhằm tăng tốc xử lý truy vấn. Vì vậy tốc độ đạt được có thể nhanh hơn 40 lần so với CPU thế hệ tương đương, ông Ian Buck cho biết.
Trở lại với Tesla T4 thì đây là mẫu GPU được Nvidia phát triển dựa trên kiến trúc Turing, tương tự RTX 20 series mà hãng giới thiệu đến người dùng cách đây không lâu. Cụ thể Tesla T4 có tổng cộng 2.560 nhân CUDA, đặc biệt là 320 nhân Tensor mang lại sự đột phá về năng lực xử tính toán dấu chấm động có độ chính xác đơn (FP32), dấu chấm động bán chính xác (FP16), số nguyên 8 bit (INT8) cũng như 4 bit (INT4).
Về kích cỡ, Tesla T4 đóng gói theo dạng card PCI Express với năng lượng tiêu thụ chỉ 75W. Theo thiết kế, mẫu GPU mới của Nvidia chạy cùng TensorRT 5, một engine được tối ưu nhằm hỗ trợ các nhân Tensor, mở rộng thiết lập mạng nơron để đáp ứng những yêu cầu cần độ chính xác bội (multi-precision) của ứng dụng máy học và AI. Bên cạnh đó, TensorRT còn hỗ trợ kiến trúc hướng dịch vụ theo mô hình microservice, đơn giản hóa mọi sự phức tạp để các dịch vụ có thể khai thác AI hiệu quả.