
Trong tuần này thì TSMC sẽ bắt đầu sản xuất chip mới trên tiến trình 3nm cho Apple. Đây là một cột mốc đáng chú ý đối với tiến trình tiên tiến nhất của TSMC vào thời điểm hiện tại. Vậy có gì đặc biệt ở N3 so với N5 và
Hôm thứ 5 vừa qua thì TSMC đã tổ chức lễ kỷ niệm mở rộng năng lực và sản lượng bán dẫn tại Fab 18 nằm, nhà máy nằm tại công viên khoa học nam Đài Loan (STSP). Fab 18 là nơi TSMC sản xuất chip trên tiến trình N3, hãng cho biết sản lượng của chip 3nm đang rất tốt và các node tiến trình lớp 3nm của TSMC đã sẵn sàng để phục vụ khách hàng trong nhiều năm tới.
Tiến trình N3 của TSMC đã bắt đầu đi vào giai đoạn sản xuất sản lượng cao (HVM) từ đầu tháng 9. Đối với TSMC thì N3 là họ tiến trình rất quan trọng bởi nó sẽ là thế hệ cuối cùng của node tiến trình dựa trên bán dẫn FinFET và là node tiến trình sẽ phục vụ cho các khách hàng trong ít nhất là 1 thập niên tới. So với tiến trình N5, N3 hứa hẹn sẽ cải thiện hiệu năng cho vi xử lý 10 - 15% ở cùng điện năng và cùng số lượng bán dẫn, giảm điện năng tiêu thụ 25 - 30% ở cùng xung nhịp và độ phức tạp của chip, và mật độ logic cao hơn khoảng 1,6 lần.
Vấn đề của N3 và xu hướng bộ đệm lớn của vi xử lý
Hôm thứ 5 vừa qua thì TSMC đã tổ chức lễ kỷ niệm mở rộng năng lực và sản lượng bán dẫn tại Fab 18 nằm, nhà máy nằm tại công viên khoa học nam Đài Loan (STSP). Fab 18 là nơi TSMC sản xuất chip trên tiến trình N3, hãng cho biết sản lượng của chip 3nm đang rất tốt và các node tiến trình lớp 3nm của TSMC đã sẵn sàng để phục vụ khách hàng trong nhiều năm tới.
Tiến trình N3 của TSMC đã bắt đầu đi vào giai đoạn sản xuất sản lượng cao (HVM) từ đầu tháng 9. Đối với TSMC thì N3 là họ tiến trình rất quan trọng bởi nó sẽ là thế hệ cuối cùng của node tiến trình dựa trên bán dẫn FinFET và là node tiến trình sẽ phục vụ cho các khách hàng trong ít nhất là 1 thập niên tới. So với tiến trình N5, N3 hứa hẹn sẽ cải thiện hiệu năng cho vi xử lý 10 - 15% ở cùng điện năng và cùng số lượng bán dẫn, giảm điện năng tiêu thụ 25 - 30% ở cùng xung nhịp và độ phức tạp của chip, và mật độ logic cao hơn khoảng 1,6 lần.
Vấn đề của N3 và xu hướng bộ đệm lớn của vi xử lý
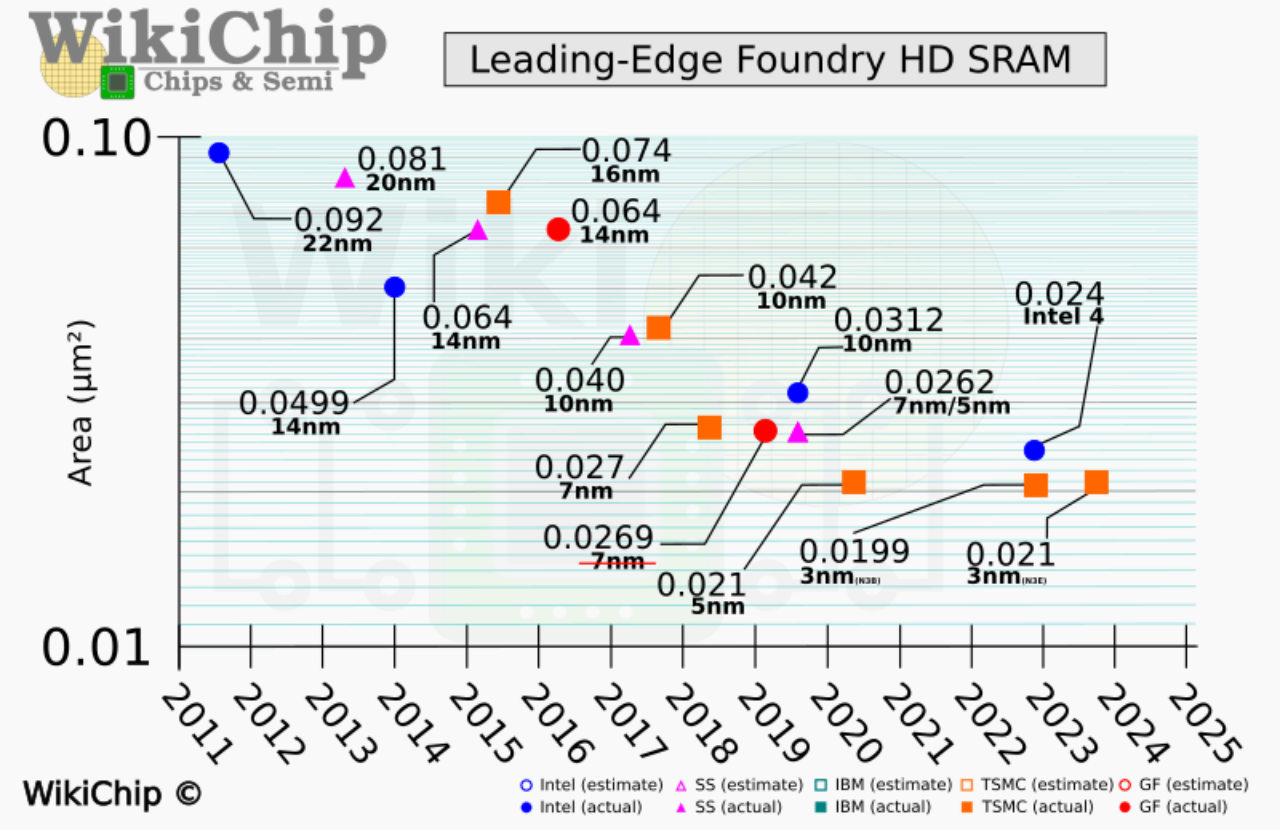
Họ tiến trình N3 của TSMC đã với biến thể N3E đang là tiến trình sản xuất được nhiều khách hàng của TSMC đặt hàng nhất nhờ sản lượng cao, hiệu năng cải thiện, điện năng tiêu thụ thấp nhưng đổi lại là chi phí của SRAM - bộ nhớ truy xuất ngẫu nhiên tĩnh, được dùng làm bộ đệm trên vi xử lý hiện đại. Theo WikiChip thì TSMC vẫn chưa thể tăng tỉ lệ của SRAM trên node tiến trình mới, kích thước của SRAM bitcell trên N3E vẫn tương tự N5 tức 0,021 µm² hay 31,8 Mib/mm² (Mebibit/mm², 1 Mebibit = 1,099 Mb = 0,13 MB) . Biến thể N3B có SRAM bitcell nhỏ hơn đôi chút ở 0,0199 µm², dung lượng sẽ đạt 33,55 Mib/mm² nhưng chỉ tăng khoảng 5% so với N5. N3B lại là biến thể có sản lượng không cao như N3E và tiến trình N3B cũng chỉ được dành cho một số thiết kế chip nhất định.
![[IMG]](https://photo2.tinhte.vn/data/attachment-files/2022/12/6283213_009_SRAM_Scaling_problem.jpg)
Cho dễ hình dung về sự chững lại của SRAM qua các thế hệ tiến trình TSMC, WikiChip đưa ra giả định như một con chip được sản xuất trên tiến trình N16 của TSMC, kích thước die vào khoảng 255 mm², có 10 tỉ bóng bán dẫn trong đó 60% dành cho mạch logic và 40% dành cho SRAM thì bộ đệm SRAM sẽ có kích thước khoảng 45 mm², chiếm 17,6% kích thước die. Khi thu nhỏ con chip này với tiến trình N5, kích thước của die sẽ còn 56 mm² và SRAM sẽ có kích thước 12,58 mm², chiếm 22,5% kích thước die. Thế nhưng nếu tiếp tục thu nhỏ bằng tiến trình N3, kích thước die còn 44 mm² nhưng SRAM vẫn có kích thước 12,58 mm², lúc này nó lại chiếm đến 30% kích thước die.
Thực tế không chỉ có TSMC gặp khó với vấn đề tăng tỉ lệ SRAM trên node tiến trình mới. Intel 4 (7nm EUV) cũng đã giảm kích thước bitcell của SRAM xuống 0,024 µm² từ 0,0312 µm² của Intel 7(10nm ESF), dung lượng của SRAM sẽ vào khoảng 27,8 Mib/mm² vẫn kém hơn so với TSMC.

Vi xử lý hiện đại như CPU, GPU, SoC sử dụng SRAM cho nhiều tầng bộ đệm khi chúng xử lý một khối lượng lớn dữ liệu. Nạp dữ liệu từ bộ nhớ hệ thống như RAM sẽ không hiệu quả do tốc độ và độ trễ lớn, đặc biệt là với những ứng dụng AI hay ML. Vi xử lý ngày nay có bộ đệm rất lớn, chẳng hạn như Ryzen 9 7950X có 81 MB cache L2 + L3, trong khi đó GPU AD102 dùng trên RTX 4090 dùng ít nhất 123 MB SRAM cho nhiều tầng bộ đệm, riêng L2 đã là 98 MB. Với xu hướng này thì trong tương lai nhu cầu về SRAM sẽ tiếp tục tăng nhưng N3 với N3E hay N3B vẫn chưa thể giảm diện tích chiệm dụng của SRAM. Điều này có nghĩa các vi xử lý hiệu năng cao vẫn cần diện tích die lớn để có thể đảm bảo diện tích cho bán dãn logic lẫn SRAM, từ đó chi phí sản xuất chip sẽ cao hơn và đặt ra nhiều thách thức cho các hãng thiết kế chip.
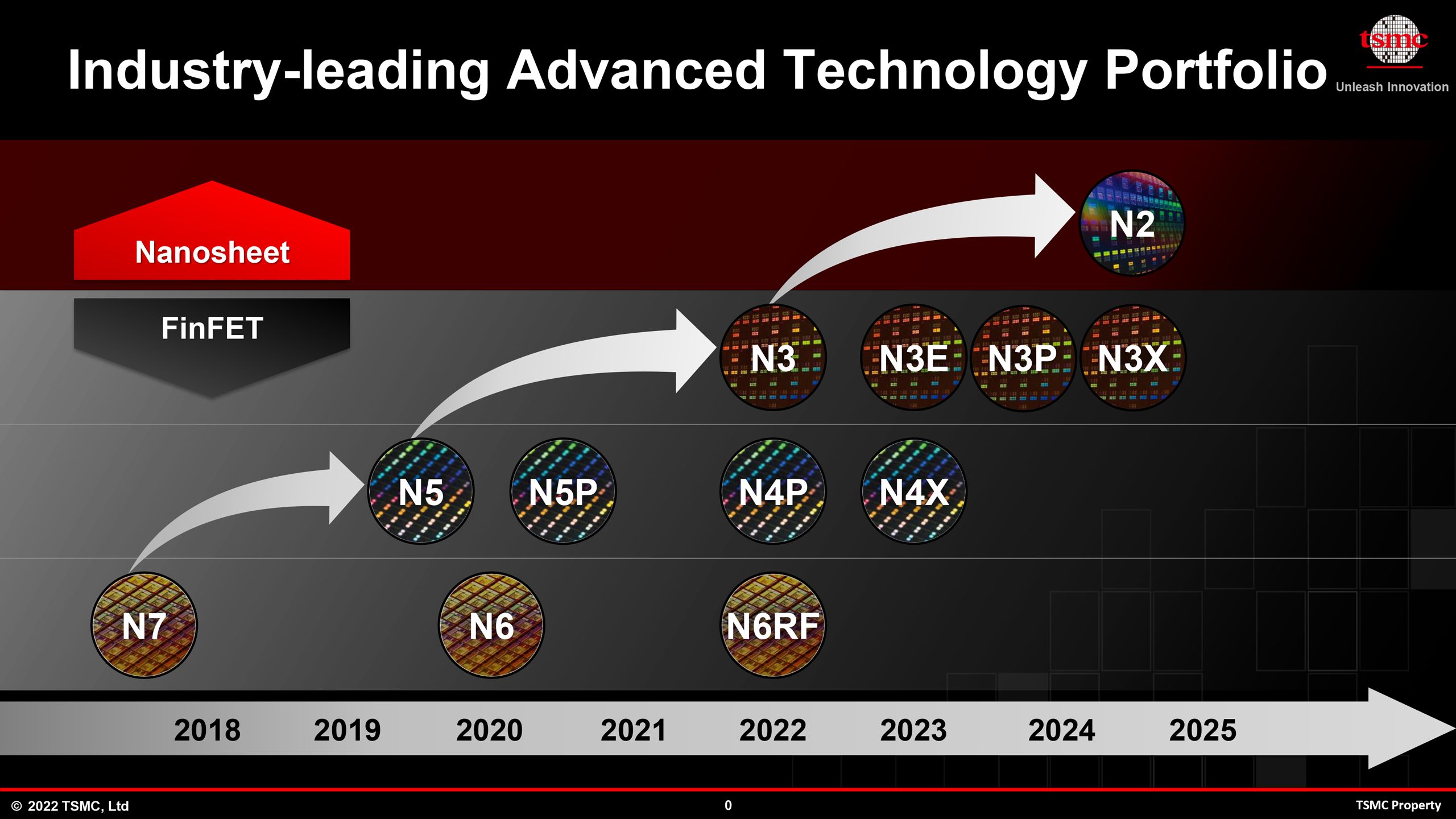
Cũng giống như bán dẫn logic, SRAM cũng dễ gặp khiếm khuyết trong sản xuất và ở thế hệ N3, TSMC cung cấp cho các nhà thiết kế chip công cụ FinFlex để phối hợp nhiều bán dẫn FinFET khác nhau trong cùng một block để tối ưu hiệu năng, điện năng tiêu thụ và diện tích. Nếu khai thác FinFlex thì hãng làm chip có thể phần nào đó giảm diện tích của SRAM bằng cách trộn lẫn SRAM cell với các bán dẫn khác. Tuy nhiên, để bitcell SRAM thật sự thu nhỏ thì các hãng phải đợi tiến trình N3S dự kiến ra mắt vào năm 2024. TSMC đã lên kế hoạch cho N3S nhằm mục tiêu tối ưu hóa mật độ bán dẫn. Dù vậy, vẫn chưa rõ tỉ lệ thu nhỏ của bitcell SRAM ở tiến trình này là bao nhiêu và liệu diện tích còn lại dành cho bán dẫn logic có đủ để đáp ứng nhu cầu hiệu năng của bán dẫn logic được thiết kế bởi AMD, Apple, NVIDIA hay Qualcomm hay không. Ngoài N3S, TSMC còn có N3X và biến thể này sẽ cải thiện về điện áp, từ đó tối ưu về hiệu năng cho các vi xử lý như CPU.
Chi phí sản xuất cao
Như đã đề cập thì nhiều đối tác lớn của TSMC đang xếp hàng chờ được sử dụng tiến trình N3. AMD, Apple, Broadcom, Intel, MediaTek, Nvidia, Qualcomm đều rất quan tâm đến N3 nhưng vẫn chưa rõ khi nào và sản phẩm nào của các hãng này sử dụng N3. Trước mắt chỉ mới Apple sử dụng N3 cho những vi xử lý tiếp theo, có thể là Apple M2 cho MacBook Pro và Mac mini thế hệ mới. Trong khi đó AMD có ý định dùng N3 để sản xuất một số vi xử lý dùng kiến trúc Zen 5 ra mắt vào năm 2024. NVIDIA thì được đồn đoán là sẽ dùng N3 cho thế hệ GPU dùng kiến trúc Blackwell cũng ra mắt vào 2024.
Quảng cáo
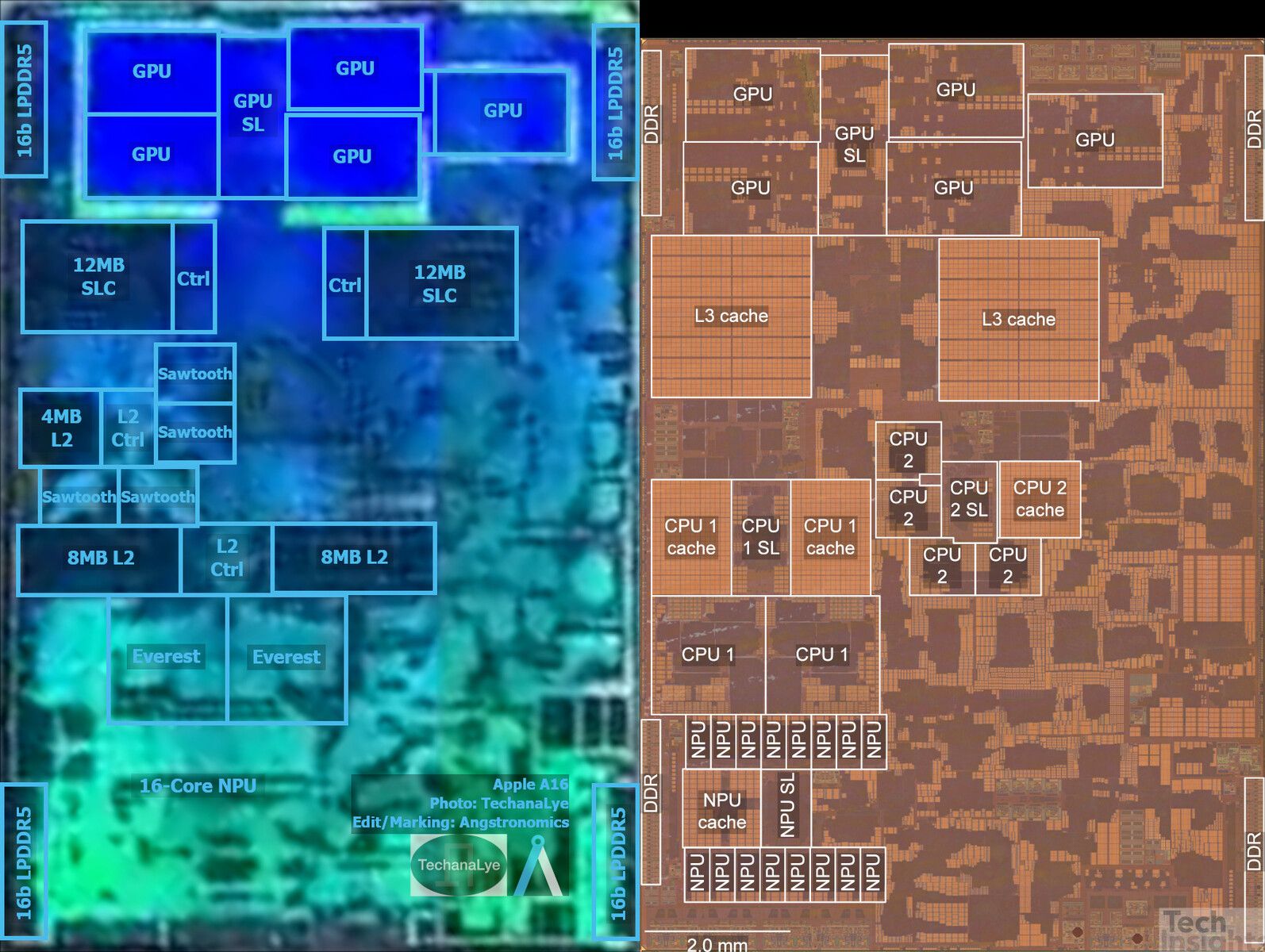
Tuy nhiên, sản xuất chip trên tiến trình N3 hiện không rẻ. Một số báo cáo cho biết TSMC có thể tính phí đến 20 ngàn đô cho mỗi tấm wafer được xử lý bằng công nghệ 3nm của mình. Giá thành sản xuất còn phụ thuộc vào nhiều yếu tố như số lượng, thiết kế, cấu hình chip. Chi phí sản xuất cao có nghĩa các nhà thiết kế chip sẽ ưu tiên dùng N3 cho những sản phẩm cao cấp nhất để tối ưu lợi nhuận. Một ví dụ như Apple đã dùng tiến trình N4 để sản xuất A16 Bionic trang bị cho iPhone 14 Pro còn dòng iPhone 14 không Pro tiếp tục dùng A15 Bionic sản xuất trên tiến trình N5P.
Tom's Hardware [1]; [2]