
Bất chấp những cải tiến liên tục và những nâng cấp đều đặn sau mỗi thế hệ, những chip vi xử lý thực sự trong một khoảng thời gian dài vẫn chưa có được những thay đổi và nâng cấp ở tầm cỡ thay đổi hoàn toàn cuộc chơi và thay đổi cả ngành. Có thể kể ra vài bước thay đổi ở tầm cỡ ấy, để anh em dễ hiểu. Đột phá là từ khi con người chuyển từ bóng đèn bán dẫn chân không sang transistor bán dẫn. Rồi đột phá kế tiếp là từng linh kiện độc lập giờ được tích hợp vào chung một mạch vi xử lý duy nhất.
Đồng ý một chuyện, transistor càng lúc càng nhỏ. Bề mặt die CPU càng lúc càng nhiều transistor, đi kèm với đó là hiệu năng tăng đáng kể so với vài chục năm về trước. Nhưng việc nhồi transistor với những tiến trình chip xử lý mới đã bắt đầu giảm về lợi thế và cải tiến. Tỷ lệ tăng trưởng hiệu năng giữa các thế hệ chip giảm dần, còn chi phí gia công chúng càng lúc càng tăng cao.
Và đây là phần cuối trong chuỗi bài về thiết kế CPU, nơi anh em có thể hiểu cơ bản và ngắn gọn lý thuyết cũng như quy trình thiết kế, sản xuất ra những con chip xử lý.
Còn ở phần cuối, là những dự báo trong tương lai. Hầu hết các tập đoàn thiết kế và sản xuất chip xử lý lớn nhất hành tinh thường không có thói quen công khai tất cả mọi thứ công nghệ họ đang nghiên cứu, hay thậm chí là cả những công nghệ bên trong sản phẩm anh em đang có thể mua ngoài tiệm vì chúng đều là bí mật kinh doanh. Nhưng dựa trên những gì được công bố chính thức, chúng ta cũng có thể phần nào xác định những xu hướng của thị trường, để xem những sản phẩm trong tương lai sẽ có gì.
Phần 1: Cơ bản kiến trúc chip xử lý máy vi tính
Đồng ý một chuyện, transistor càng lúc càng nhỏ. Bề mặt die CPU càng lúc càng nhiều transistor, đi kèm với đó là hiệu năng tăng đáng kể so với vài chục năm về trước. Nhưng việc nhồi transistor với những tiến trình chip xử lý mới đã bắt đầu giảm về lợi thế và cải tiến. Tỷ lệ tăng trưởng hiệu năng giữa các thế hệ chip giảm dần, còn chi phí gia công chúng càng lúc càng tăng cao.
Và đây là phần cuối trong chuỗi bài về thiết kế CPU, nơi anh em có thể hiểu cơ bản và ngắn gọn lý thuyết cũng như quy trình thiết kế, sản xuất ra những con chip xử lý.
Còn ở phần cuối, là những dự báo trong tương lai. Hầu hết các tập đoàn thiết kế và sản xuất chip xử lý lớn nhất hành tinh thường không có thói quen công khai tất cả mọi thứ công nghệ họ đang nghiên cứu, hay thậm chí là cả những công nghệ bên trong sản phẩm anh em đang có thể mua ngoài tiệm vì chúng đều là bí mật kinh doanh. Nhưng dựa trên những gì được công bố chính thức, chúng ta cũng có thể phần nào xác định những xu hướng của thị trường, để xem những sản phẩm trong tương lai sẽ có gì.
Phần 1: Cơ bản kiến trúc chip xử lý máy vi tính
Phần 2: Quy trình thiết kế chip CPU
Phần 3: Dàn bề mặt và quang khắc chip CPU
Phần 4: Xu hướng tương lai, và những chủ đề nóng của kiến trúc chip xử lý máy tính
Định luật Moore, trong vòng 125 năm qua
Một trong những lý thuyết quen thuộc và được nhắc đến nhiều nhất trong ngành chip xử lý chính là định luật Moore, nơi ngài Gordon Moore, đồng sáng lập tập đoàn Intel năm xưa đưa ra dự đoán, hay đúng hơn là mục tiêu rằng, số lượng transistor trên mỗi con chip tăng gấp đôi sau 18 tháng. Trong một khoảng thời gian rất dài, nhiều thập kỷ, tiên đoán và roadmap này của ngài Moore chính xác. Nhưng giờ mọi chuyện đã khác. Mật độ transistor trên một con chip không còn tăng gấp đôi sau một năm rưỡi đến 2 năm, thậm chí là 3 năm nữa.
Thành ra ngài CEO Jensen Huang cứ nhắc đi nhắc lại rằng định luật Moore đã chết.
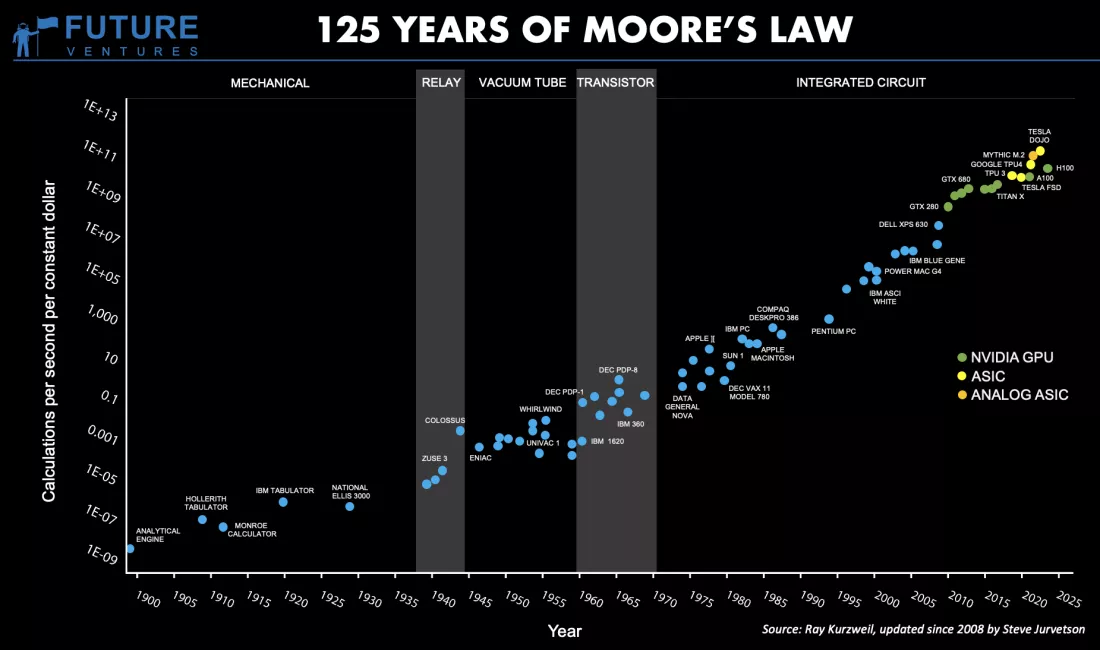
Transistor giờ nhỏ tới mức chuẩn bị chạm tới giới hạn vật lý của công nghệ quang khắc silicon. Đối với những CPU phổ biến nhất hiện giờ, cơ bản thì đúng là không thể áp dụng được định luật Moore nữa. Tốc độ tăng trưởng mật độ transistor trên bề mặt die bán dẫn đã giảm rất mạnh. Vì thế, Intel, AMD hay TSMC đã phải chuyển hướng sang nghiên cứu phát triển những công nghệ khác như kỹ thuật đóng gói chip mới, phát triển kiến trúc chiplet, và xếp chồng die chip 3D.
Một trong những hệ quả trực tiếp của xu hướng này chính là việc số lượng nhân xử lý logic của những CPU càng lúc càng tăng, thay vì chỉ nâng xung nhịp tối đa mà con chip có thể vận hành. Đấy là lý do giờ có những CPU 64, 128 hay thậm chí là 192 nhân, từ tiêu dùng tới doanh nghiệp, thay vì hai nhân nhưng chạy ở 10 GHz.
Điện toán lượng tử
Quảng cáo
Ở một khía cạnh hoàn toàn khác, điện toán lượng tử lại là một khía cạnh đầy tiềm năng có thể khai thác và phát triển được trong tương lai. Thế nhưng ngoại trừ khái niệm Qubit, nơi một bit dữ liệu có thể mang nhiều giá trị khác nhau chứ không chỉ có nhị phân tuyệt đối, hoặc 0 hoặc 1, và những gì các tập đoàn đã công bố trong thời gian gần đây, bản thân công nghệ điện toán lượng tử vừa mới, vừa đang được hoàn thiện, mà đến chính những ứng dụng thực tế của máy tính lượng tử cũng chưa được xác định một cách chính xác.
Phải khẳng định luôn, máy tính lượng tự không phải thứ cho phép anh em chơi Cyberpunk 2077 ở tốc độ 1000 FPS, hay tạo ra những hình ảnh render đồ họa máy tính đẹp như đời thật. Thứ mà máy tính lượng tử có thể giải quyết, là chạy những thuật toán và phần mềm mà máy tính nhị phân truyền thống không thể nào hoàn thành trong khoảng thời gian hợp lý, hoặc không thể chạy nổi.

Nói cách khác, trên khía cạnh khoa học công nghệ, máy tính lượng tử nếu đi đúng hướng, có thể giải quyết được rất nhiều vấn đề để cải thiện cuộc sống con người, theo cách cho phép các nhà khoa học máy tính tạo ra những mô hình điện toán khác biệt hoàn toàn.
Nhưng cho tới khi máy tính lượng tử trở nên phổ biến, có lẽ phải đợi 1, 2 thập kỷ, thậm chí có khi lâu hơn. Chưa kể, cũng chẳng thể dùng máy tính lượng tử để làm nhiều công việc chuyên nghiệp như sáng tạo nội dung, dựng clip chỉnh hình hay làm đồ họa 3D được.
Xu hướng điện toán hiệu năng cao, và AI
Xu hướng rõ ràng nhất ngay ở thời điểm hiện tại là điện toán không đồng nhất. Gọi giải pháp này là heterogeneous computing, vì các hãng đều đang muốn tích hợp nhiều cụm transistor phục vụ xử lý các tác vụ điện toán khác nhau vào cùng một hệ thống. Một ví dụ rõ ràng nhất, là cỗ máy tính của anh em cắm thêm card đồ họa rời, với một GPU độc lập, RAM cũng độc lập, để tăng tốc xử lý game.
Quảng cáo
Một chip CPU rất dễ tinh chỉnh, làm được rất nhiều việc vì là một chip vi xử lý phổ quát, ở tốc độ tương ứng với mức độ phức tạp của tác vụ được yêu cầu. Còn trong khi đó, GPU trong máy tính hay laptop của anh em được thiết kế với hàng nghìn nhân tính toán, chỉ được tối ưu để thực hiện những phép tính như cộng trừ nhân chia ma trận. So với CPU, GPU xử lý logic rất tệ. Nhưng so với GPU, CPU tính nhân ma trận hay tính toán vector, rồi tensor chậm hơn nhiều.
Chuyển những phép tính mà GPU được thiết kế để xử lý chuyên biệt, tốc độ tính toán sẽ nhanh hơn. Và đương nhiên, đối với mọi dev, tối ưu phần mềm bằng cách tinh chỉnh thuật toán thì luôn dễ hơn tối ưu phần cứng.

Rồi từ GPU, bắt đầu thấy các hãng tạo ra những chip xử lý tối ưu riêng cho nhu cầu huấn luyện hay vận hành những thuật toán machine learning, thứ cấu thành một mô hình ngôn ngữ AI, cơn sốt của toàn thế giới hơn hai năm nay. Google có TPU, viết tắt của Tensor Processing Unit. Nvidia tạo ra những sản phẩm như A100 hay H200, chỉ có nhân tensor, chuyên biệt vận hành deep learning. AMD có Instinct MI300, và Intel thì có Gaudi, sắp ra mắt thế hệ thứ 3.
Tương tự như vậy là trong những sản phẩm tiêu dùng, từ máy tính cá nhân tới smartphone. Những con chip xử lý cho điện thoại và laptop giờ có cả những cụm nhân tăng tốc xử lý một hoặc một vài tác vụ rất cụ thể. Như trong M4 của Apple chẳng hạn, ngoài cụm nhân CPU và GPU, còn có cả Neural Engine tăng tốc xử lý AI, rồi ISP xử lý tín hiệu hình ảnh, cụm mã hóa/giải mã codec video, rồi thậm chí có cả chip tăng tốc xử lý bảo mật…
Xu hướng này được gọi là Sea of Accelerators.
Khi tác vụ xử lý càng lúc càng chuyên biệt, các nhà phát triển phần cứng cũng cần kết hợp càng lúc càng nhiều cụm nhân hoặc chip tăng tốc xử lý. AWS giờ cung cấp cả dịch vụ vận hành chip FPGA tùy chỉnh tự do để các dev tăng tốc xử lý các tác vụ trên máy chủ đám mây. Không như những kiến trúc cố định từ khâu thiết kế như CPU và GPU, FPGA tùy chỉnh cực kỳ tự do, một dạng phần cứng lập trình lại được công năng theo ý muốn.
Nhưng FPGA vẫn còn một đối thủ khác, là ASIC. Ngày xưa ASIC có tiếng tăm từ những cỗ máy chuyên biệt đào Bitcoin, còn giờ những con chip ASIC, viết tắt của application-specific integrated circuits. Hiện tại Google, Tesla và Cerebras đều đang tập trung phát triển ASIC để tối ưu nghiên cứu huấn luyện mô hình AI.

Xu hướng khác, trong ngành điện toán tiêu dùng, là việc chuyển dịch sang thiết kế chiplet, tạo ra những SoC, hay còn gọi là System on a Chip, đầy đủ mọi cụm nhân xử lý phục vụ gần hết mọi nhu cầu xử lý trong thiết bị công nghệ. Những con chip die monolithic truyền thống rất khó đẩy quy mô và mật độ transistor cũng như sản xuất hiệu quả từng cụm nhân xử lý. Vậy là AMD, Qualcomm, Intel rồi Apple bắt đầu chuyển sang nghiên cứu phát triển những thiết kế dạng module, nhiều cụm nhân xử lý kset hợp lại với nhau thành một package hoàn chỉnh.
Nhìn vào hình chụp dieshot của vài con chip xử lý smartphone ra mắt gần đây, anh em có thể thấy, khu vực nhân CPU không hề chiếm vị trí trung tâm, càng không có diện tích lớn nhất trên một die silicon. Một phần rất lớn của con chip là những nhân tăng tốc xử lý AI, hay bộ xử lý tín hiệu điện tử. Nhờ đó, chip vừa tiết kiệm điện, vừa có tốc độ xử lý nhanh hơn so với việc chỉ ứng dụng nhân CPU thông thường.

Trước kia muốn thêm tính năng xử lý tín hiệu video vào một hệ thống, sẽ phải sản xuất nguyên một con chip riêng chỉ để làm việc đó. Cứ khi nào tín hiệu phải đi ra đi vào những con chip khác nhau, điện năng yêu cầu để xử lý chúng tăng theo. Dù rằng một phần rất nhỏ của một Joule công suất điện nghe có vẻ không đáng là bao, nhưng ở một thiết bị tối ưu thời lượng pin, đó là lượng điện hao phí rất lớn, nhất là khi anh em làm phép tính, điện năng tiêu thụ khi xử lý dữ liệu trên cùng một con chip luôn thấp hơn 3 đến 4 lần so với việc đem nó ra xử lý trên con chip bên ngoài.
Đương nhiên những chip tăng tốc chuyên biệt cũng không hoàn hảo. Thêm càng nhiều những cụm nhân như vậy, toàn bộ SoC sẽ càng bớt đa dụng, phải đánh đổi khả năng điện toán phổ quát lấy hiệu năng tối đa nhưng chỉ cho vài tác vụ đơn lẻ. Việc cân bằng giữa hai khía cạnh này liên tục được các hãng điều chỉnh. Và thậm chí còn có cả một khái niệm mô tả giữa sự phổ quát với sự chuyên biệt: Specialization gap.
Điện toán gần bộ nhớ, cùng những sáng tạo trong ngành
Một khía cạnh khác các nhà thiết kế chip đang muốn cải thiện hiệu năng là bộ nhớ. Thông thường một trong những nút nghẽn cổ chai lớn nhất trong quá trình xử lý điện toán chính là đọc và ghi dữ liệu vào bộ nhớ. Đấy là lý do bộ nhớ đệm nhanh và dung lượng cao có thể giúp cải thiện hiệu năng. Nhưng vẫn sẽ có những lúc cần phải lấy dữ liệu từ RAM, hay thậm chí là cả SSD. Quá trình này sẽ tiêu tốn hàng nghìn chu kỳ xung nhịp.
Thành ra các kỹ sư đều coi khả năng truy xuất dữ liệu từ bộ nhớ luôn tốn kém hơn chính bản thân nâng cấp về hiệu năng xử lý.
Nếu chip xử lý của anh em muốn cộng hai giá trị, đầu tiên nó sẽ phải tính địa chỉ bộ nhớ, xác định vị trí của dữ liệu đầu vào trong toàn bộ phân cấp bộ nhớ, kéo giá trị đó vào thanh ghi, thực hiện tính toán, rồi tính địa chỉ lưu trữ giá trị đầu ra, rồi mới ghi giá trị đã tính toán. Đối với những tác vụ đơn giản chỉ mất một hoặc hai chu kỳ nhịp là xong, điều này vô cùng không hiệu quả.
Một ý tưởng mới đang có rất nhiều kỹ thuật nghiên cứu được tạo ra thời gian gần đây là một thứ viết tắt là NMC - Near Memory Computing. Thay vì chuyển những mẩu dữ liệu nhỏ từ bộ nhớ vào một chip xử lý tốc độ cao để tính toán, các nhà nghiên cứu đảo ngược ý tưởng này hoàn toàn. Họ tạo ra khả năng tính toán trực tiếp vào cả cụm nhân điều khiển bộ nhớ, module RAM, hay thậm chí là cả trong SSD.
Một giải pháp con thuộc kỹ thuật NMC gọi là PIM - Processing In Memory, nhắm tới khả năng thực hiện tính toán ngay ở nơi dữ liệu được lưu trữ, cắt bỏ cả độ trễ lẫn lượng điện năng cần để xử lý với chip xử lý và RAM như truyền thống.

Ba cái tên lớn nhất trong ngành chip nhớ, Samsun, SK Hynix và Micron đều đang nghiên cứu công nghệ chip nhớ xếp chồng HBM nhưng có thêm cả tính năng PIM, kết hợp những cụm nhân tính toán logic bên trong những lớp chip nhớ chồng lên nhau. Đối với Samsung, chip HBM-PIM của họ đã thể hiện được cải thiện hiệu năng hai con số phần trăm đối với các tác vụ AI, điện toán đám mây và điện toán hiệu năng cao, nhờ vào việc giảm tần suất phải di chuyển dữ liệu qua lại chip nhớ và chip xử lý.
Một giải pháp sáng tạo khác là CXL - Compute Express Link. Đây là công nghệ cầu nối tốc độ cao, đồng bộ với bộ nhớ đệm, cho phép đổ dữ liệu vào bộ nhớ chung, rồi xử lý điện toán gần bộ nhớ. Trong những data center vận hành AI, Intel, AMD và Nvidia đã bắt đầu ứng dụng mở rộng bộ nhớ dựa trên kỹ thuật CXL này để cùng lúc nhiều chip xử lý có thể dùng chung nguồn dữ liệu trong bộ nhớ. Kỹ thuật này cho phép triệt tiêu nghẽn cổ chai trong điện toán truyền thống, nơi khả năng truy xuất dữ liệu của CPU từ bộ nhớ là thứ giới hạn tốc độ tính toán.

Đương nhiên những kỹ thuật kể trên vẫn còn những rào cản, đặc biệt nhất trong số đó là những giới hạn của quy trình gia công bán dẫn. Trong phần 3 anh em đã đọc, gia công bán dẫn wafer silicon cực kỳ phức tạp, với vài chục bước. Quy trình ấy vì vô cùng đắt đỏ, nên thường chỉ dành cho nhu cầu gia công những cụm nhân xử lý logic mật độ transistor rất cao, hoặc bộ nhớ mật độ cell nhớ cao.
Nếu sản xuất CPU bằng quy trình gia công chip RAM, mật độ transistor sẽ bị ảnh hưởng. Còn nếu sản xuất chip RAM bằng quy trình gia công CPU, dung lượng mỗi cell nhớ và mật độ cell nhớ sẽ bị ảnh hưởng.
Tích hợp 3D: Bước kế tiếp của thiết kế chip xử lý
Một giải pháp khác đầy tiềm năng để giảm thiểu nghẽn cổ chai giữa CPU và DRAM là tích hợp chip theo cả trục ngang lẫn trục dọc, gọi là 3D Integration.
Những con chip truyền thống, phổ biến nhất hiện nay thường chỉ được xử lý quang khắc một lớp transistor. Cách tiếp cận này đương nhiên có giới hạn. Giải quyết những giới hạn này là xếp chồng từng lớp transistor lên nhau để cải thiện cả mật độ, băng thông và giảm độ trễ. Mỗi lớp transistor này có thể được gia công trên những tiến trình và kỹ thuật khác nhau, rồi kết nối bằng một cầu nối gọi là TSV - Through Silicon Via, hoặc kỹ thuật hybrid bonding.
Thành công nhất, phổ biến nhất và nổi tiếng nhất trên thị trường điện toán tiêu dùng hiện giờ chính là những SSD với những con chip 3D NAND. Hiện giờ, những chip vi xử lý hiệu năng cao cũng đã bắt đầu ứng dụng ý tưởng tương tự. Đầu tiên là AMD, họ xếp chồng một die bộ nhớ đệm công nghệ 3D-Vcache lên trên cụm CCX 8 nhân 16 luồng của Ryzen 7 5800X3D, thành công trong việc tách rời cụm bộ nhớ đệm L3 dung lượng lớn ra khỏi thiết kế CPU truyền thống, tạo ra một sản phẩm với hiệu năng đa nhân khủng khiếp.
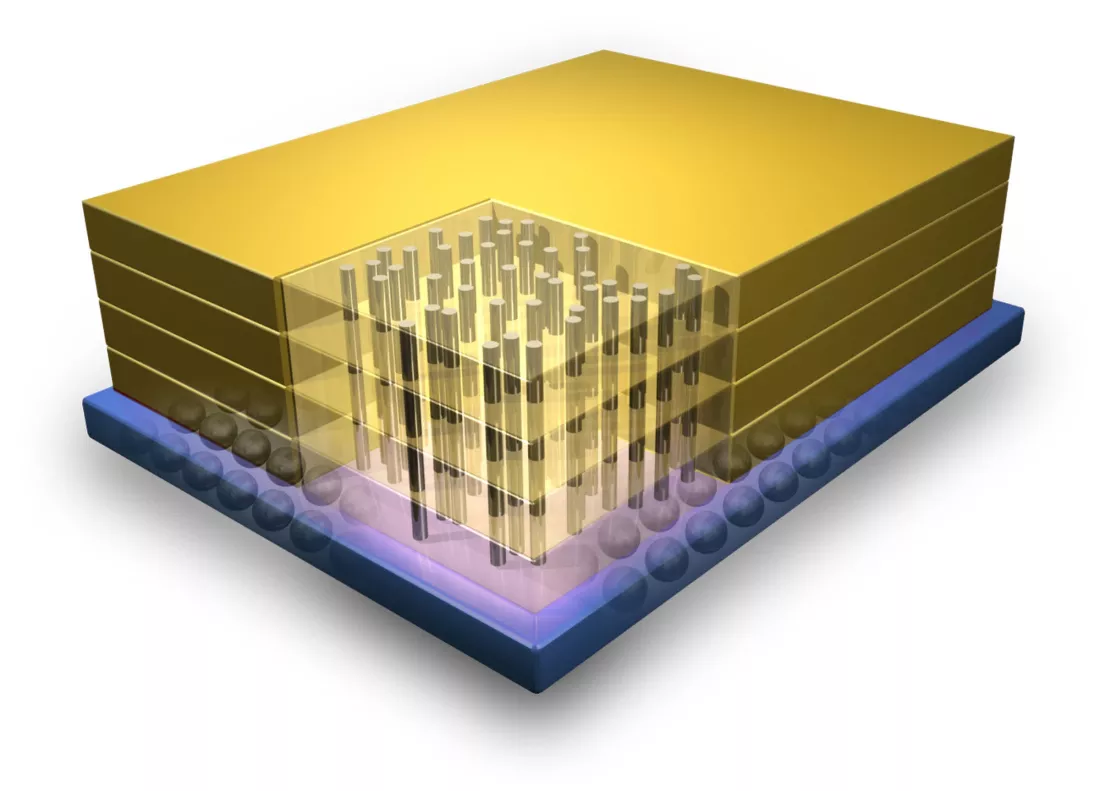
Tương tự như vậy là Foveros của Intel, nhưng tham vọng của họ là xếp chồng nhiều lớp transistor xử lý logic, từ đó cho phép gia công nhiều chi tiết và cụm chip với nhiệm vụ khác nhau một cách độc lập rồi ghép lại, thay vì phải dàn mọi thứ lên một die silicon duy nhất.

Một giải pháp đã được thương mại hóa khác, là HBM, High Bandwidth Memory. Những chip DRAM xếp chồng lên nhau này, kết nối với nhau bằng cầu nối TSV đã trở thành tiêu chuẩn cho những chip xử lý tăng tốc AI, GPU máy chủ và những chip xử lý trong data center, nhờ vào băng thông rất lớn, tiêu thụ điện thấp hơn do với công nghệ DDR truyền thống.
Những xu hướng trong tương lai
Ngoài những thay đổi và cải tiến về mặt vật lý và kiến trúc, một xu hướng định hình ngành công nghiệp bán dẫn là tập trung nhiều hơn vào bảo mật. Cho đến gần đây, bảo mật trong bộ xử lý phần nào là một ý tưởng thêm vào sau cùng. Tương tự như cách internet, email và nhiều hệ thống khác mà chúng ta ngày nay vô cùng phụ thuộc, hầu hết đều được thiết kế với rất ít sự quan tâm đến bảo mật. Bất kỳ tính năng bảo mật nào có trên chip thường được bổ sung sau đó để mọi người cảm thấy an toàn hơn.
Với CPU, tư duy này cuối cùng đã quay lại, khiến các tập đoàn khổ sở. Những lỗ hổng như Spectre và Meltdown khét tiếng là những ví dụ đáng sợ ban đầu về lỗ hổng trong hệ thống thực thi suy đoán, và gần đây hơn, các cuộc tấn công kênh phụ như Zenbleed, Downfall và Hertzbleed đã chỉ ra rằng kiến trúc bộ xử lý hiện đại vẫn có những lỗ hổng bảo mật lớn.
Do đó, các nhà sản xuất CPU giờ đang phải thiết kế chip với các tính năng bảo mật tích hợp như tính toán bảo mật, mã hóa bộ nhớ và vùng an toàn (secure enclave).

Trong các phần trước của loạt bài này, chúng ta đã bàn tới các kỹ thuật như Tổng hợp cấp cao (High-Level Synthesis - HLS), thứ cho phép các nhà thiết kế chỉ định thiết kế phần cứng bằng ngôn ngữ cấp cao, trước khi sử dụng các thuật toán tối ưu hóa do AI điều khiển, để tạo ra các bản vẽ thiết kế mạch bán dẫn tốt nhất có thể. Khi chi phí phát triển chip tiếp tục tăng vọt, ngành công nghiệp bán dẫn ngày càng dựa vào thiết kế phần cứng hỗ trợ phần mềm và các công cụ xác minh thiết kế hỗ trợ bằng AI để tối ưu hóa sản xuất.
Tuy nhiên, khi kiến trúc máy tính truyền thống tiến gần đến giới hạn hiệu năng, các nhà nghiên cứu đang khám phá các mô hình máy tính hoàn toàn mới có thể định nghĩa lại cách chúng ta xử lý thông tin. Hai trong số những hướng triển vọng nhất là máy tính hình thái thần kinh và máy tính quang học, nhằm mục đích khắc phục những điểm nghẽn cơ bản của chip bán dẫn thông thường.

Máy tính mô phỏng hình thái thần kinh là một lĩnh vực mới nổi, mô phỏng cách não bộ con người xử lý thông tin, sử dụng mạng lưới các tế bào thần kinh và khớp thần kinh nhân tạo thay vì các cổng logic truyền thống.

Trong khi đó, máy tính quang học thay thế các mạch điện tử truyền thống bằng bộ xử lý quang sử dụng ánh sáng thay vì điện để truyền và xử lý thông tin. Vì photon di chuyển nhanh hơn và ít bị cản trở hơn electron, nên máy tính quang học có tiềm năng vượt trội hơn ngay cả những chip bán dẫn tiên tiến nhất trong một số tác vụ nhất định.
Mặc dù chẳng mấy ai trong số chúng ta dự đoán được tương lai, nhưng những ý tưởng sáng tạo và những lĩnh vực nghiên cứu được đề cập trên đây nhiều khả năng sẽ đóng vai trò trở thành lộ trình cho những gì chúng ta có thể mong đợi trong các thiết kế bộ xử lý trong tương lai. Điều chúng ta biết chắc chắn là chúng ta đang tiến gần đến hồi kết của quy trình gia công bán dẫn truyền thống, mở rộng quy mô và mật độ transistor như hàng chục năm qua. Để tiếp tục tăng hiệu suất qua mỗi thế hệ, các nhà thiết kế sẽ cần đưa ra các giải pháp phức tạp hơn nữa.
Theo Techspot

