Cách đây vài ngày OpenAI bất ngờ cho ra mắt AI tạo video từ text nhập vào khiến giới AI nói riêng và cả thế giới công nghệ nói chung "rúng động". Trên thực tế, việc tạo ra video bằng AI không quá lạ lẫm, nhưng tạo ra video từ những đoạn text như thuật toán Sora thì thực sự là một cột mốc cực kỳ đáng chú ý.
Bên dưới đây là đoạn video OpenAI cung cấp do Sora tạo ra với prompt: A cat waking up its sleeping owner demanding breakfast. The owner tries to ignore the cat, but the cat tries new tactics and finally the owner pulls out a secret stash of treats from under the pillow to hold the cat off a little longer. Mặc dù đây chỉ là bản thử nghiệm nhưng những cảnh mà Sora tạo ra đã là quá chân thực, khiến cho ranh giới giữa video quay bằng camera ngoài đời thật và video tạo ra ngày càng mong manh đi hơn nữa.
Vậy nguyên nhân vì sao đây là sự kiện chấn động, và cách hoạt động của Sora ra sao thì mời anh em tìm hiểu chung với mình.
Bên dưới đây là đoạn video OpenAI cung cấp do Sora tạo ra với prompt: A cat waking up its sleeping owner demanding breakfast. The owner tries to ignore the cat, but the cat tries new tactics and finally the owner pulls out a secret stash of treats from under the pillow to hold the cat off a little longer. Mặc dù đây chỉ là bản thử nghiệm nhưng những cảnh mà Sora tạo ra đã là quá chân thực, khiến cho ranh giới giữa video quay bằng camera ngoài đời thật và video tạo ra ngày càng mong manh đi hơn nữa.
Vậy nguyên nhân vì sao đây là sự kiện chấn động, và cách hoạt động của Sora ra sao thì mời anh em tìm hiểu chung với mình.
AI tạo sinh làm được những gì trước giờ?
Sơ qua một chút, AI tạo sinh là một dạng AI có thể tạo ra nội dung, ý tưởng mới dưới dạng các cuộc trò chuyện, câu chuyện biểu diễn bằng văn bản, hình ảnh, video và âm thanh. Nó cố gắng bắt chước trí thông minh của con người như nhận dạng hình ảnh, xử lý ngôn ngữ tự nhiên (NLP) và dịch thuật ngôn ngữ.
Trong thế giới AI tạo sinh sẽ có các mô hình khác nhau, từ các mô hình hồi quy (sử dụng thông tin từ bước trước để tạo ra nội dung tiếp theo, thí dụ mạng nơ ron hồi quy RNN tạo văn bản từ một mô hình ngôn ngữ), cho tới mô hình tạo ảnh như diffusion. Các mô hình AI này xưa giờ đã có thể tạo văn bản từ văn bản, tạo hình ảnh từ văn bản, tạo hình ảnh từ hình ảnh và cả tạo video / ảnh động từ hình ảnh / video. Mỗi cái đều có điểm mạnh và giới hạn khác nhau.
Sora AI làm được gì?
Tương tự, Sora là một mô hình tạo sinh hoàn toàn mới và linh hoạt, cho phép tạo ra hình ảnh và video với các tỷ lệ khung hình, độ phân giải và thời lượng tùy theo ý muốn của người dùng. Phổ quát nhất, thì Sora kết hợp giữa kiến trúc diffusion (tạo ảnh) và kiến trúc transformer (xử lý các kiểu tác vụ NLP). Về khả năng, Sora AI có các tính năng:
- Text-to-video: Như chúng ta đã thấy
- Hình ảnh thành video: Mang lại sức sống cho hình ảnh tĩnh
- Video-to-video: Thay đổi phong cách (màu, tương phản, ánh sáng, shadow,....) của video thành một cái gì đó khác
- Kéo dài thời gian video: bản chất là play video xuôi, xong play ngược lại.
- Tạo các vòng lặp mãi mãi: loop một video
- Tạo hình ảnh tĩnh độ phân giải lên đến 2048 x 2048
- Tạo video ở bất kỳ định dạng nào: Từ 1920 x 1080 đến 1080 x 1920 và các định dạng ở giữa.
- Mô phỏng thế giới ảo: Giống như Minecraft và các game tương tự.
- Tạo một video: Độ dài lên đến 1 phút với nhiều đoạn ngắn bên trong.
Sora AI khác biệt như thế nào so với các AI tạo sinh trước giờ?
Như đã nói ở trên, dùng AI để tạo ra video thì không mới. Nói nôm na, hãy tưởng tượng thế giới này là 1 nhà bếp. Các mô hình tạo video xưa giờ là một anh đầu bếp với khả năng nấu ăn theo cuốn sách công thức. Ở đây, video đầu ra chính là "món ăn" và thuật toán là "công thức nấu ăn". Các đầu bếp khi đó sẽ dùng những nguyên liệu đặc biệt (định dạng dữ liệu) và kỹ thuật nấu (kiến trúc của mô hình) để từ đó tạo ra các món ăn (video) từ món đơn giản như mì gói (video ngắn) tới các món phức tạp như mì ý sốt bò bằm (video với định dạng đặc biệt nào đó).
Đối với Sora, anh em cứ hình dung nó giống như một đầu bếp đẳng cấp hơn, hiểu được bản chất của nguyên liệu nấu ăn và hương vị món ăn. Với khả năng này, ông đầu bếp này không cần dùng công thức coi trên mạng hay trong sách dạy nấu ăn, mà sẽ sáng tạo ra món ăn mới. Anh đầu bếp này có thể linh hoạt sử dụng nguyên liệu (data) và kỹ thuật (kiến trúc của mô hình), từ đó tạo ra những đoạn video với chất lượng cao, nhiều tùy chọn.
Điểm độc đáo của Sora AI là gì?
Để nấu được món ngon, anh đầu bếp Sora AI đã có một bí quyết đặc biệt: chính là Spacetime Patches (tạm dịch là Các mảng Không - Thời gian).
Quảng cáo
Khái niệm Spacetime Patches được đề cập trong trong một nghiên cứu của Google DeepMind về NaVit và ViT (Vision Transformers), dựa trên một nghiên cứu khác hồi 2021 tên là An Image is Worth 16x16 Words (đây là một nghiên cứu rất nổi tiếng để giải quyết các bài toán về thị giác máy tính, lấy cảm hứng tới việc ứng dụng kiến trúc Transformer vào xử lý ngôn ngữ tự nhiên. Cái này dài và hay lắm, anh em nào muốn tìm hiểu thì nên đọc thêm ha)
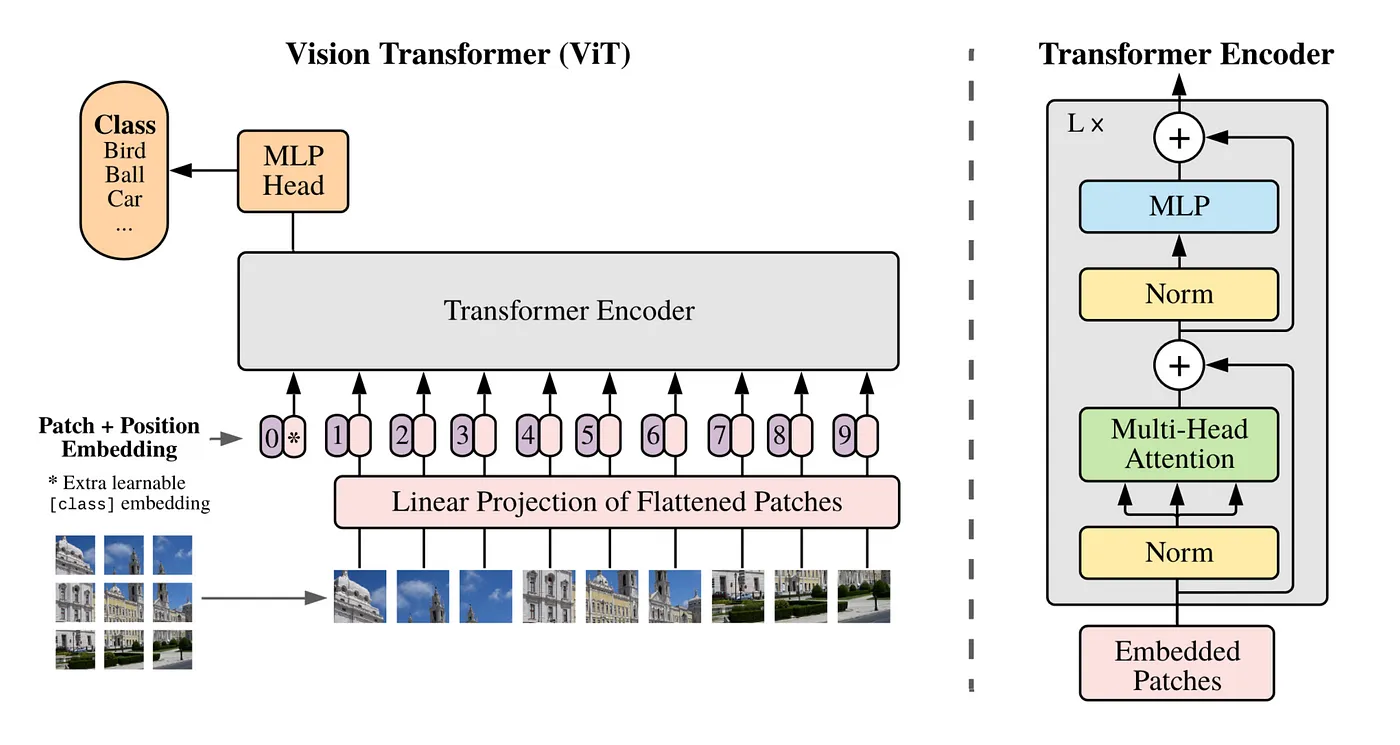
Một cách nôm na, hình ảnh đầu vào đầu tiên sẽ được "băm" thành những mảng nhỏ hơn. Vision Transformers sẽ dùng một chuỗi các "mảng pixel" này để train cho mô hình nhận diện được những thứ trong hình ảnh, cuối cùng phân loại nó đâu là hình chó, đâu là hình mèo, trái cây,... thay vì phân loại bằng từ ngữ như mô hình language transformer. Đối với Vision Transformers, máy tính sẽ coi hình ảnh đầu vào được cấu thành từ các mảng các pixel và nó phụ thuộc vào độ phân giải của hình ảnh đầu vào cố định (dài x rộng x dày).

Tiếp theo, các mảng pixel này sẽ được xử lý bởi mạng nơ ron tích chập (CNN) để phân loại đối tượng. Nói thì đơn giản như thực ra, thuật toán phải trải qua các khâu tiền xử lý như trích xuất đặc điểm của các mảng dựa vào coi nó như ma trận rất lớn các pixel, sau đó làm các phép toán so sánh, nhân chia cộng trừ ma trận, rồi resize, padding này nọ để phát hiện viền vật thể, làm mờ, làm nét,.... Và nên nhớ, đây chỉ là 1 tấm hình mà đã xử lý cực như vậy, còn video là một chuỗi những frame hình thì lại càng phức tạp hơn.
Chí mạng hơn nữa, do bản chất của thuật toán như vậy nên cùng 1 bức ảnh đầu vào, nhưng xử lý 2 lần sẽ cho ra 2 bức ảnh khác nhau, luôn có sai khác giữa một số điểm ảnh được sinh ra sau mỗi lần tạo ảnh. Nên xưa giờ các video sinh ra do AI đều không ổn định, chính xác là không mượt. Anh em cứ thử coi 1 video mà AI tạo ra the cách cũ, liên tục bấm dừng lại sẽ thấy mỗi frame hình là 1 bức ảnh khác nhau chứ không mượt như SoraAI.
Quảng cáo
Nói cách khác, Vision Transformers bị phụ thuộc vào tập dữ liệu hình ảnh train đầu vào với tỷ lệ và kích thước cố định, nên đầu ra cũng bị giới hạn, lại cần phải tốn rất nhiều nguồn lực tiền xử lý hình ảnh.

Bằng cách tiếp cận tương tự như cách xử lý hình ảnh của NaViT, Sora AI chọn cách giữ cố định tỷ lệ và độ phân giải gốc của hình ảnh, đồng thời nó coi một video là "chuỗi của các mảng pixel". Việc "giữ cố định" này đóng vai trò quan trọng để nắm bắt được bản chất thật sự của dữ liệu hình ảnh, giúp cho mô hình có thể "hiểu" thế giới chính xác hơn, từ đó giúp Sora tạo ra được những video có độ chân thực rất cao.
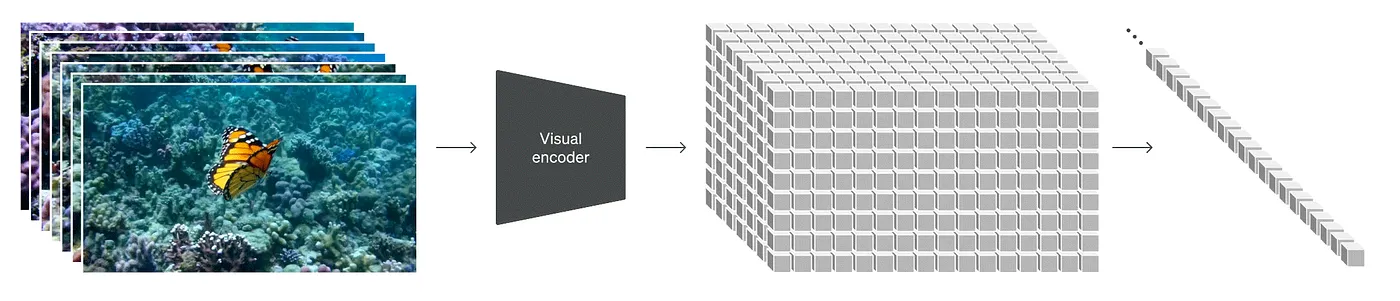
Phương pháp này giúp Sora có thể tạo một chuỗi các frame hình (bản chất tạo video) một cách đơn giản mà không mất nhiều nguồn lực, lại xử lý được chuyện lặp đi lặp lại tạo ảnh đơn dẫn tới sai khác mỗi lần tạo. Nói cách khác, Sora có thể đồng loạt xử lý một chuỗi các mảng mà không cần phải tiền xử lý lại. Chính sự "linh hoạt" này đảm bảo mọi phần của dữ liệu đều có vai trò ngang nhau trong việc giúp mô hình "hiểu", tương tự như trong nấu ăn, nguyên liệu nào cũng quan trọng vậy.
Sau khi hiểu xong vật thể trong hình đó là cái gì bằng cách chia ra thành mảng không thời gian như trên, Sora hoàn toàn có thể áp thêm các mô phỏng nguyên tắc vật lý giống như đời thật cùng nhiều thuật toán khác để tạo nên các cảnh không gian 3 chiều nhất quán.
Sora AI cần phải được dạy như thế nào?
Chất lượng và sự đa dạng của dữ liệu đào tạo có vai trò rất quan trọng khi làm các mô hình AI tạo sinh. Các mô hình video hiện tại theo truyền thống được đào tạo dựa trên một bộ dữ liệu hạn chế hơn, thời lượng ngắn hơn và mục tiêu rất giới hạn do phải đảm bảo các "chuẩn" vốn bị giới hạn.
Đối với Sora, tập dữ liệu đưa vào sẽ thoải mái hơn, video hay hình ảnh ở độ phân giải nào, tỷ lệ ra sao, dài ngắn thế nào đều được. Dựa vào đó, nó sẽ tạo ra được nhiều thứ hơn. Thí dụ gần đây OpenAI nói nó tạo ra được cả thế giới trong Minecraft, tạo ra cả gameplay, rồi mô phỏng lại các cảnh quay được người ta tạo ra bằng Unreal hoặc Unity trong bộ data huấn luyện để nắm hiểu được các góc máy, các phong cách video.
Việc dạy "toàn diện" như thế cho phép Sora có thể linh động trong "hiểu biết" và tạo ra nội dung video cũng vừa đa dạng định dạng, vừa có chất lượng hình ảnh cao. Và đây chính xác là cách tiếp cận mà các mô hình ngôn ngữ được dạy bằng đa dạng các bộ dữ liệu văn bản, chỉ khác là thay vì dạy bằng text thì bây giờ người ta dạy Sora bằng nội dung hình ảnh.
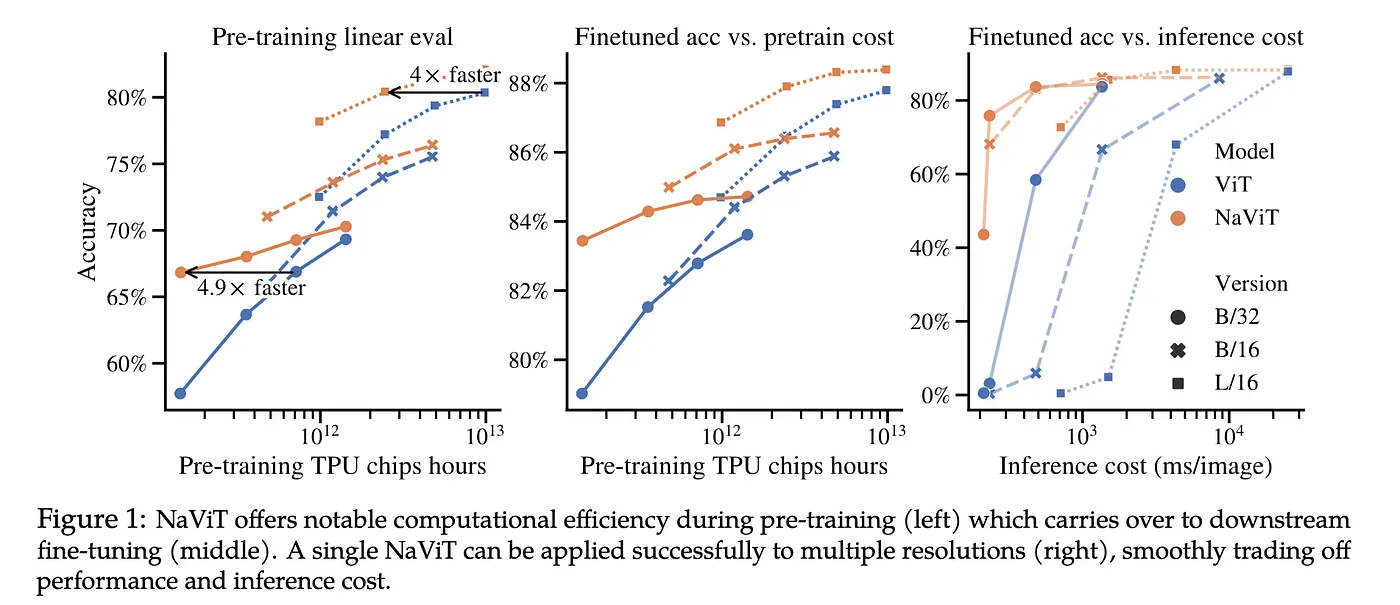
Nhờ vào việc sử dụng nguyên lý train mô hình tương tự như NaViT, Sora AI cũng được train bằng cách gom đóng gói nhiều mảng lại với nahu thành một chuỗi đơn, sau đó tận dụng các mảng không thời gian để tạo ra video ngon hơn. Cách tiếp cận này giúp nó "học giỏi" hơn từ một tập dữ liệu rộng hơn, qua đó cải thiện khả năng tạo video với độ trung thực cao mà không cần tính toán phức tạp như các mô hình trước giờ.
Khả năng hiểu được thế giới vật lý và không gian 3 chiều
Việc tái tạo video với không gian và các vật thể không bị biến dạng chính là điểm ăn tiền của Sora AI khi xem các đoạn demo của ní. Bằng cách đào tạo trước loạt các dữ liệu video mà không cần điều chỉnh hoặc xử lý trước, Sora có thể học được cách mô hình hóa thế giới vật lý với độ chính xác rất cao, tương tự như những hình ảnh đầu vào mà nó được dạy ban đầu.
Với khả năng đó, Sora có thể tạo ra những thế giới ảo và tất nhiên là video với các vật thể, nhân vật chuyển động trong đó, tương tác với nahu trong không gian 3 chiều ảo. Nói cách khác, đoạn video mà chúng ta xem tạo ra bởi Sora chỉ là một góc nhìn trong thế giới mà nó đã tạo ra, và đáng chú ý hơn, nó tạo ra vô hạn các thế giới như vậy. Ngâm cứu tới đây mình còn đang tự hỏi là có khi mình có sống trong thế giới ảo như trong phim không trời.
Tham khảo OpenAI RS