Intel Xeon Scalable thế hệ 4 có tên mã là Sapphire Rapids, vừa ra mắt chính thức vào ngày 10/1/2023. Những vi xử lý này được sản xuất trên tiến trình 10 nm Enhanced SuperFin, không chỉ có thay đổi về vi kiến trúc mà còn trang bị thêm nhiều công nghệ mới, điển hình như bộ nhớ liên tục Intel Optane DC, các bộ tăng tốc tích hợp (on-die accelerator) và CXL (Compute Express Link). Đối với các tác vụ trung tâm dữ liệu, Sapphire Rapids mang đến lợi thế nhờ có nhiều nhân, tăng số chỉ lệnh trong mỗi chu kỳ, tăng Intel UPI GT/s, tăng dung lượng bộ đệm, tăng bộ nhớ MT/s, bổ sung thêm làn CXL và PCI Express.
Thế hệ bộ nhớ liên tục Intel Optane tiếp theo là dạng bộ nhớ có thể hoạt động ở cả dạng khả biến (volatile) và bất biến (non-volatile), trở thành 1 sản phẩm nằm giữa ổ lưu trữ và DRAM. Anh em khi sử dụng RAM máy tính là loại bộ nhớ khả biến, dữ liệu lưu trên đó chỉ tồn tại khi còn được cung cấp năng lượng (điện), nếu không, toàn bộ dữ liệu sẽ biến mất. Ngược lại, non-volatile memory vẫn duy trì được tính toàn vẹn dữ liệu ngay cả khi mất điện. Bộ nhớ liên tục của Intel có thể định địa chỉ theo byte (byte addressable), liên kết với bộ đệm, cho phép phần mềm truy cập trực tiếp mà không cần phân trang. Intel Optane DC Persistent Memory 300 Series hỗ trợ các chế độ hoạt động gồm App Direct (AD), Memory Mode (MM) và Mixed Mode (AD + MM). Tính năng bảo mật của bộ nhớ liên tục 300 Series là +FIPS140-3 level 2 thay vì mã hóa AES-256 như thế hệ trước.

Thế hệ Intel Optane DC Persistent Memory 300 Series hỗ trợ các hoạt động của bộ nhớ liên tục từ xa (RPMEM - remote persistent memory). Điều này giúp Intel Data Direct I/O (Intel DDIO) có thể tương tác từ xa với bộ nhớ, giúp giảm điện năng và tăng băng thông. RPMEM cũng bổ sung thêm các hoạt động ghi nguyên tử (atomic write operation - hoạt động ghi bộ nhớ không thể bị ngắt quãng) cho RDMA (Remote Direct Memory Access), trong khi hoạt động đọc RDMA không còn phải chờ đợi dữ liệu được đẩy tới miền ADR (Asynchronous DRAM Refresh). Tổng kết lại thì RPMEM loại bỏ sự góp mặt của phần mềm trong quá trình sao chép, nhờ đó giảm thời gian chờ đợi. RPMEM tương thích với ACPI (Advanced Configuration and Power Interface), cho phép bộ nhớ liên tục được xử lý ở mọi nơi và IO chuyển hướng trực tiếp đến bộ nhớ liên tục hoặc khả biến.
Intel Optane DC Persistent Memory 300 Series
Thế hệ bộ nhớ liên tục Intel Optane tiếp theo là dạng bộ nhớ có thể hoạt động ở cả dạng khả biến (volatile) và bất biến (non-volatile), trở thành 1 sản phẩm nằm giữa ổ lưu trữ và DRAM. Anh em khi sử dụng RAM máy tính là loại bộ nhớ khả biến, dữ liệu lưu trên đó chỉ tồn tại khi còn được cung cấp năng lượng (điện), nếu không, toàn bộ dữ liệu sẽ biến mất. Ngược lại, non-volatile memory vẫn duy trì được tính toàn vẹn dữ liệu ngay cả khi mất điện. Bộ nhớ liên tục của Intel có thể định địa chỉ theo byte (byte addressable), liên kết với bộ đệm, cho phép phần mềm truy cập trực tiếp mà không cần phân trang. Intel Optane DC Persistent Memory 300 Series hỗ trợ các chế độ hoạt động gồm App Direct (AD), Memory Mode (MM) và Mixed Mode (AD + MM). Tính năng bảo mật của bộ nhớ liên tục 300 Series là +FIPS140-3 level 2 thay vì mã hóa AES-256 như thế hệ trước.
Thế hệ Intel Optane DC Persistent Memory 300 Series hỗ trợ các hoạt động của bộ nhớ liên tục từ xa (RPMEM - remote persistent memory). Điều này giúp Intel Data Direct I/O (Intel DDIO) có thể tương tác từ xa với bộ nhớ, giúp giảm điện năng và tăng băng thông. RPMEM cũng bổ sung thêm các hoạt động ghi nguyên tử (atomic write operation - hoạt động ghi bộ nhớ không thể bị ngắt quãng) cho RDMA (Remote Direct Memory Access), trong khi hoạt động đọc RDMA không còn phải chờ đợi dữ liệu được đẩy tới miền ADR (Asynchronous DRAM Refresh). Tổng kết lại thì RPMEM loại bỏ sự góp mặt của phần mềm trong quá trình sao chép, nhờ đó giảm thời gian chờ đợi. RPMEM tương thích với ACPI (Advanced Configuration and Power Interface), cho phép bộ nhớ liên tục được xử lý ở mọi nơi và IO chuyển hướng trực tiếp đến bộ nhớ liên tục hoặc khả biến.
Chỉ lệnh mới
Một phần của chỉ lệnh mới tập trung vào AiA (Accelerator interfacing Architecture), tích hợp vào ISA (Instruction Set Architecture) và là 1 cải tiến trên bộ xử lý x86 nhằm tối ưu hóa đường đi dữ liệu từ bộ tăng tốc đến nơi lưu trữ. Các chỉ lệnh MOVDIR, MOVDIR64B, ENQCMD, ENQCMDS, User Interrupts, User IPIs, Umonitor, Umwait và PAUSE tập trung vào thao tác AiA. MOVDIR/MOVDIR64B giúp giảm tải di chuyển dữ liệu đến bộ tăng tốc. ENQCMD/ENQCMDS tạo điều kiện thuận lợi cho các hàng chờ công việc chia sẻ và riêng biệt, cho phép phần cứng quản lý quy trình, tránh lãng phí tài nguyên xử lý trên 1 chuỗi liên tục. User Interrupts, User IPIs, Umonitor, Umwait, và PAUSE xử lý các khía cạnh tín hiệu và đồng bộ hóa của bộ tăng tốc.
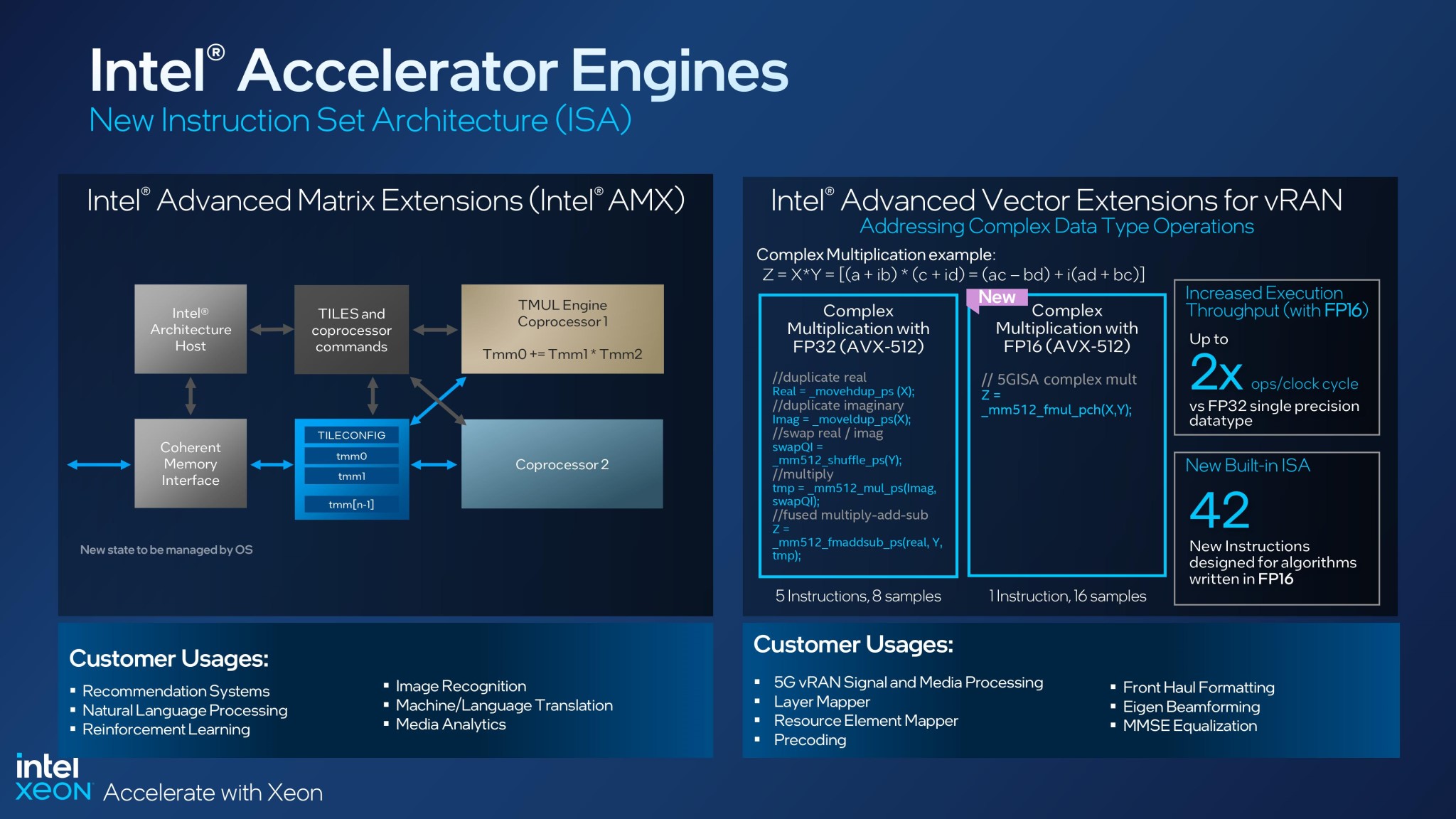
Các chỉ lệnh hỗ trợ AI thông qua Intel AMX bao gồm Int8 để suy luận, Bfloat16 để suy luận/huấn luyện và Xsave giúp quản lý hệ điều hành của các khối silicon chuyên dụng. Intel AVX-512 có VP2INTERSECT để cải thiện vector hóa và mã vô hướng. FP16 sao chép chỉ lệnh tính toán FP32(SP) sử dụng kiểu dữ liệu FP16 mới để hỗ trợ số phức, có giá trị với xử lý tín hiệu và hình ảnh, đặc biệt là mạng 5G.
Đối với ảo hoá, HLAT (Hypervisor Linear Address Translation) có thể được VMM (Virtual Machine Manager) sử dụng để dịch địa chỉ tuyến tính (linear) sang địa chỉ vật lý (physical). Kết hợp với bảng - trang nâng cao, HLAT giúp đảm bảo các bản dịch do VMM thực thi không bị giả mạo bởi những phần mềm hệ thống không đáng tin cậy.
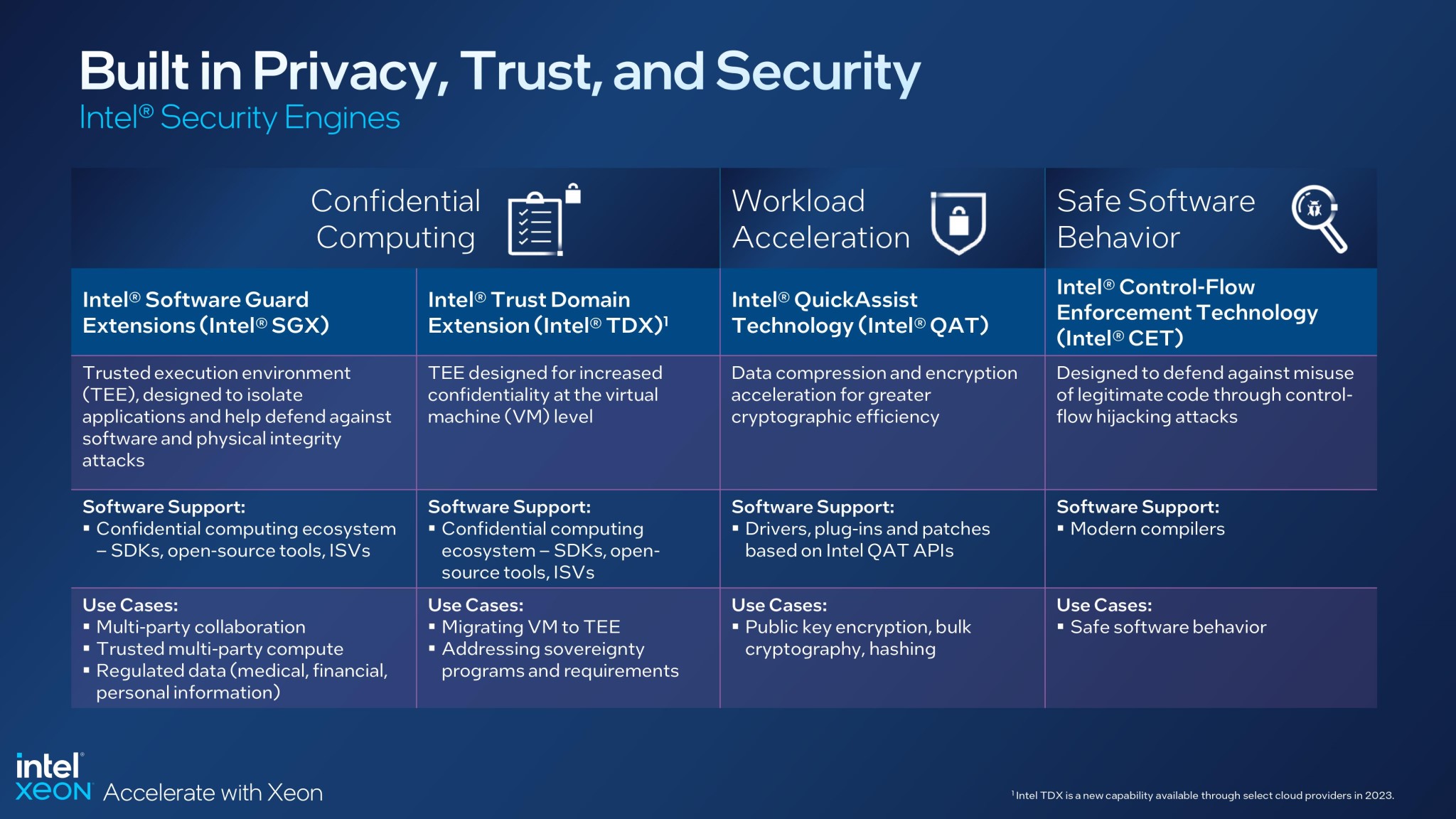
Khía cạnh bảo mật, công nghệ Intel CET (Control-Flow Enforcement Technology) bảo vệ shadow stack (stack biệt lập chỉ chứa return address) bằng cách triển khai bản sao shadow stack do CPU quản lý. Cả 2 shadow stack này sẽ được so sánh khi CALL để đảm bảo không có sự khác biệt nào không mong muốn. Cuối cùng, Intel TSX (Transactional Synchronization Extensions) cũng có 2 chỉ lệnh mới, gồm XSUSLDTRK và XRESLDTRK, cho phép lập trình viên chọn việc truy cập bộ nhớ nào không cần theo dõi trong bộ đọc TSX.
Bộ tăng tốc tích hợp

Quảng cáo
Sapphire Rapids được tích hợp sẵn nhiều bộ tăng tốc vào vi xử lý, mang đến những chức năng và tính năng mới để hỗ trợ cho AI, mật mã, phân tích cơ sở dữ liệu trong bộ nhớ, cũng như hoạt động truyền tải dữ liệu. Các bộ tăng tốc cũng góp phần tối ưu thông lượng mã vì chúng ở gần với vi xử lý hơn. Accelerator có thể hoạt động đơn lẻ hoặc kết hợp nhằm tăng hiệu suất nhờ cách tiếp cận đa lớp. Những bộ tăng tốc mới gồm có Intel QAT (QuickAssist Technology) thế hệ mới, Intel IAA (In-Memory Analytics Accelerator), Intel DSA (Data Streaming Accelerator) và Intel AMX (Advanced Matrix Extensions).
Tăng tốc mật mã học
Public Key là loại mật mã được sử dụng rộng rãi để xác thực và trao đổi khóa khi thiết lập kết nối an toàn TLS (Transport Layer Security) giữa 2 hệ thống. Dựa trên phép toán số nguyên lớn, các mật mã yêu cầu tính toán phép nhân và bình phương nguyên hàm cường độ cao để hỗ trợ thuật toán mật mã. Chỉ lệnh AVX512 IFMA (Integer Fused Multiply Add) VPMADD52 hỗ trợ các phép toán nhân số lớn hiệu quả cùng khả năng xử lý song song tăng gấp 4 lần so với các kiến trúc trước đây. Hiệu năng của mật mã Public Key RSA, ECDSA và ECDHE có thể được cải thiện khi kết hợp các chỉ lệnh này vào nguyên hàm tính toán thuật toán cụ thể.

Các mã đối xứng AES (Advanced Encryption Standard) có thể được tối ưu hóa để tận dụng lợi thế của Vectorized AES-NI. Khi sử dụng với các thanh ghi độ rộng 512 bit, chúng có thể xử lý tối đa 4 khối AES 128-bit trên mỗi chỉ lệnh, cải thiện đáng kể về thông lượng mã hóa hàng loạt ở nhiều chế độ khác nhau, ví dụ như AES-GCM.
Sự xuất hiện của Vectorized Carryless Multiply (CLMUL) và SHA-Extensions trong kiến trúc sẽ hỗ trợ cho các thuật toán băm mã. Vectorized CLMUL tăng thông lượng cho xử lý Galois Hash (GHASH) cùng các chỉ lệnh cụ thể được bổ sung để hỗ trợ SHA-256, cải thiện hiệu suất so với các kiến trúc Xeon Scalable trước đây. Các chỉ lệnh mới tương thích với Data Plane Development KIT DPDK, Intel OpenSSL Engine, Intel Storage Acceleration library (ISAL), IPSec Multi-Buffer Library và IPP Multi-Buffer Library.
Intel QAT thế hệ cũ nằm ở chipset, trong khi với Sapphire Rapids thì đã được chuyển vào chung gói vi xử lý, nhờ đó tối ưu được tương tác do khoảng cách vật lý ngắn hơn. Intel QAT mới cung cấp 200Gbs Crypto, 160Gbs verified compression, 100kops PFS ECDHE và RSA 2K Decrypt.
Quảng cáo
Intel Advanced Matrix Extensions

Intel AMX được thiết kế để cải thiện hiệu suất đào tạo và suy luận học sâu. Đây là mô hình lập trình 64-bit mới gồm 2 thành phần: tập hợp các thanh ghi 2 chiều (tile) đại diện cho các mảng con từ ảnh bộ nhớ 2 chiều lớn hơn, và bộ tăng tốc có thể hoạt động trên các tile này, với triển khai đầu tiên gọi là TMUL (tile matrix multiply unit). Intel AMX cung cấp các cỡ tile có thể cấu hình cho lập trình viên để cung cấp linh hoạt dưới dạng siêu dữ liệu (metadata). Một chỉ lệnh duy nhất có thể tự động thực hiện nhiều chu kỳ trong tile và phần cứng tăng tốc. Do quá trình thực thi thông qua metadata nên hệ nhị phân Intel AMX có thể dễ dàng tận dụng những thay đổi theo thời gian về kích thước tile mà không cần điều chỉnh mã phần mềm.
Compute Express Link
CXL là 1 chuẩn kết nối mở, sử dụng lớp vật lý PCI Express Gen 5, cung cấp khả năng di chuyển dữ liệu ở cấp nhân (kernel) giữa vi xử lý và các thiết bị khác như FPGA (Field Programmable Gate Array), GPU (Graphics Processor Unit) hoặc điều khiển mạng. CXL cho phép truy cập bộ đệm kết hợp từ các thiết bị này đến bộ đệm của vi xử lý, cũng như truy cập bộ nhớ từ bộ xử lý đến bộ nhớ trên thiết bị. Những bộ tăng tốc tích hợp như Intel IAA, Intel DSA, Intel QAT và Intel AMX sử dụng CXL để tối ưu hóa.