
Mấy tháng trước, Stability AI giới thiệu mô hình Stable Diffusion XL. Một trọng tâm cơ bản của SD XL là việc nó được tạo ra hướng tới việc nội suy những tấm hình với độ chân thực rất cao, thứ đã tạo ra danh tiếng của công cụ cạnh tranh trực tiếp với SD, Midjourney kể từ khi phiên bản v5 chính thức ra mắt. Những yếu tố như chi tiết gương mặt và bố cục tấm hình sẽ là thứ được cải thiện rất nhiều ở SD XL, so với những model và checkpoint dựa trên SD 2.0 và 2.1.
Theo Stability UI, SD XL vận hành như thế này. Checkpoint đầu tiên thực hiện tạo hình ở độ phân giải thấp, gọi là Base model. Hình ảnh được tạo ra sẽ có độ phân giải 128x128 pixel. Kế đến, hình ảnh siêu nhỏ này sẽ được cho chạy tăng độ phân giải cũng như chi tiết hình ảnh lên 1024x1024 pixel. Đây là kích thước mà Stability AI tuyên bố là độ phân giải lý tưởng, mô hình SD XL được huấn luyện.
![[IMG]](https://photo2.tinhte.vn/data/attachment-files/2023/07/6496254_pipeline.png)
Ngày 18/7 tới, SD XL phiên bản 1.0 sẽ được ra mắt chính thức. Nhưng nhiều ngày qua, SD XL 0.9 đã bị rò rỉ trên mạng internet. Hệ quả là Stability AI đã tung ra bản “nghiên cứu thử nghiệm” của SD XL 0.9, ai muốn đăng ký để tải về cũng được hết, và cho phép chạy local trên máy tính cá nhân của anh em, với điều kiện máy đủ cấu hình yêu cầu để tạo ra những tấm hình dựa trên thuật toán AI.

Theo Stability UI, SD XL vận hành như thế này. Checkpoint đầu tiên thực hiện tạo hình ở độ phân giải thấp, gọi là Base model. Hình ảnh được tạo ra sẽ có độ phân giải 128x128 pixel. Kế đến, hình ảnh siêu nhỏ này sẽ được cho chạy tăng độ phân giải cũng như chi tiết hình ảnh lên 1024x1024 pixel. Đây là kích thước mà Stability AI tuyên bố là độ phân giải lý tưởng, mô hình SD XL được huấn luyện.
Ngày 18/7 tới, SD XL phiên bản 1.0 sẽ được ra mắt chính thức. Nhưng nhiều ngày qua, SD XL 0.9 đã bị rò rỉ trên mạng internet. Hệ quả là Stability AI đã tung ra bản “nghiên cứu thử nghiệm” của SD XL 0.9, ai muốn đăng ký để tải về cũng được hết, và cho phép chạy local trên máy tính cá nhân của anh em, với điều kiện máy đủ cấu hình yêu cầu để tạo ra những tấm hình dựa trên thuật toán AI.
Đây chỉ là những trải nghiệm mang tính vui vẻ, để xem sức mạnh của SD XL so sánh như thế nào với Midjourney hay Dall-E. Thực tế nếu anh em muốn tạo hình từ AI, kể cả Stable Diffusion 1.5 hay 2.1, anh em có thể lựa chọn giải pháp Automatic1111 WebUI, mình đã có bài hướng dẫn chi tiết. Anh em có thể đọc lại ngay dưới đây.
Còn nếu muốn trải nghiệm SD XL mà máy tính không đủ sức mạnh, thì Clipdrop cũng có giải pháp cho anh em tạo hình miễn phí, mỗi ngày 60 hình, rất thoải mái, xử lý hoàn toàn bằng máy chủ của Stability AI, mở web lên là làm được:

Hướng dẫn anh em cài Stable Diffusion, tạo hình bằng AI miễn phí nhờ máy tính cá nhân
Hiện giờ đã có rất nhiều giải pháp tạo hình ảnh từ những câu lệnh anh em đưa ra. Midjourney giờ thu tiền hàng tháng để anh em lên Discord gửi câu lệnh tạo hình ảnh. Bing Chat với sức mạnh của DALL-E cho anh em tạo ra những hình ảnh cơ bản nhờ sức…
tinhte.vn

Mời anh em dùng thử miễn phí Stable Diffusion XL trên web, mỗi ngày tạo được 60 hình
Stability AI ít ngày trước vừa công bố bản thử nghiệm của mô hình ngôn ngữ Stable Diffusion XL. Điều đáng nói nhất của màn ra mắt này, Stability AI tuyên bố sau khi phát triển xong Stable Diffusion XL, nó sẽ là một mô hình ngôn ngữ mã nguồn mở…
tinhte.vn
Yêu cầu cơ bản của SD XL 0.9 và ComfyUI, là máy tính của anh em phải có tối thiểu 32GB RAM, GPU 16GB VRAM, tốt nhất là dùng card đồ họa Nvidia. Lý do là ComfyUI tải toàn bộ mô hình refiner của SD XL 0.9 vào RAM. Cũng nhờ cái bài trải nghiệm này mà mình phát hiện ra… máy tính mình vừa chết một thanh RAM, giờ chỉ còn có 16GB. Thời điểm hình ảnh được xử lý qua mô hình refiner, máy coi như đứng im không làm gì được, cho tới khi tải xong checkpoint để xử lý hình ảnh.
Tải checkpoint SDXL
Đầu tiên, anh em vào đường link này: stabilityai/stable-diffusion-xl-base-0.9 · Hugging Face
Anh em sẽ phải tạo tài khoản, đồng ý với những điều khoản sử dụng phiên bản thử nghiệm 0.9 của SD XL. Sau đó Stability AI sẽ cho anh em tải gói dữ liệu về máy tính.
Quảng cáo
Trong gói dữ liệu này có rất nhiều file khác nhau, nhưng anh em chỉ cần quan tâm đến hai file duy nhất:
- sd_xl_base_0.9.safetensors
- sd_xl_refiner_0.9.safetensors
Sau khi đã có checkpoint SD XL 0.9, giờ là đến đoạn chọn công cụ để vận hành checkpoint, tạo hình bằng những câu lệnh của anh em.
ComfyUI hay Automatic1111 WebUI?
Ba ngày trước, WebUI đã có cập nhật riêng hỗ trợ tạo hình bằng SD XL 0.9. WebUI về cơ bản là một trong những công cụ phổ biến nhất cho anh em vọc vạch làm hình ảnh bằng thuật toán AI, những mô hình của Stability UI, hoặc do những người khác huấn luyện dựa trên những mô hình như SD 1.5, 2.0 và 2.1…
Tuy nhiên cách vận hành của WebUI khi tạo hình bằng SD XL 0.9 có hai bất cập. Thứ nhất là anh em chỉ được chọn một trong hai checkpoint base hoặc refiner để tạo hình. Dùng checkpoint base thì hình ảnh rất thô, còn dùng refiner thì chi tiết bị ảnh hưởng nghiêm trọng, người có 5 6 bàn tay, chân mất một hoặc thừa một, vì bản chất cách vận hành của SD XL đã được mô tả ở trên.

Quảng cáo
Vậy là chúng ta có một giải pháp khác, ComfyUI. Với ComfyUI, anh em sẽ được dùng cả hai checkpoint một cách hiệu quả, đúng theo cách mà SD XL vận hành để tạo hình bằng thuật toán AI. Lợi thế thứ hai, theo trải nghiệm của mình, là tài nguyên mà ComfyUI sử dụng nếu so với việc tạo hình bằng WebUI là thấp hơn nhiều. Cũng là một tấm hình 1024x1024 pixel, WebUI ngốn đủ 16GB VRAM trên chiếc RTX 4080. Còn ComfyUI trong toàn bộ quá trình tạo hình, chỉ dùng có hơn một nửa số đó.
Anh em tải ComfyUI và bỏ checkpoint SD XL vào folder theo các bước sau:
- Truy cập trang GitHub của ComfyUI: GitHub - comfyanonymous/ComfyUI: A powerful and modular stable diffusion GUI with a graph/nodes interface.
- Ở mục Installing, anh em click vào dòng Direct link to Download. Phiên bản này bao gồm toàn bộ những file cài đặt cần thiết để vận hành trên máy tính chạy Windows, và GPU Nvidia. Chỉ cần tải gói này về là anh em sẽ tiết kiệm được một khoản thời gian để setup phần mềm vận hành.
- Tải xong file ComfyUI_windows_portable_nvidia_cu118_or_cpu.7z, anh em giải nén ở ổ cứng mong muốn.
- Sau đó, mở folder ComfyUI_windows_portable_nvidia_cu118_or_cpu, tìm đến đường dẫn ComfyUI_windows_portable\ComfyUI\models\checkpoints.
- Trong folder checkpoints, anh em bỏ hai file checkpoint sd_xl_base_0.9.safetensors và sd_xl_refiner_0.9.safetensors.
- Quay lại folder ComfyUI_windows_portable, sẽ có hai file bat để khởi động ComfyUI. Anh em sẽ dùng file run_nvidia_gpu.bat để bắt đầu.
- Mở file run_nvidia_gpu.bat, chờ setup chạy xong, trang web local để tạo hình bằng AI sẽ hiện ra ngay, không phải gõ địa chỉ như WebUI. Nhưng anh em khoan bắt đầu tạo hình ngay, mà hãy tải một cái workspace để làm việc hoàn hảo nhất với SD XL trước.
- Anh em truy cập https://pastebin.com/sjhP8Pcj, tải file json về. Đây là layout để xử lý tạo hình ảnh bằng SD XL, thông qua cả hai checkpoint base và refiner.
- Ở giao diện của ComfyUI, anh em sẽ ấn nút Load ở bảng lệnh xử lý hình ảnh, tải file json vừa download về máy vào giao diện ComfyUI. Đến lúc này giao diện tạo hình ảnh bằng AI trông sẽ giống như thế này:
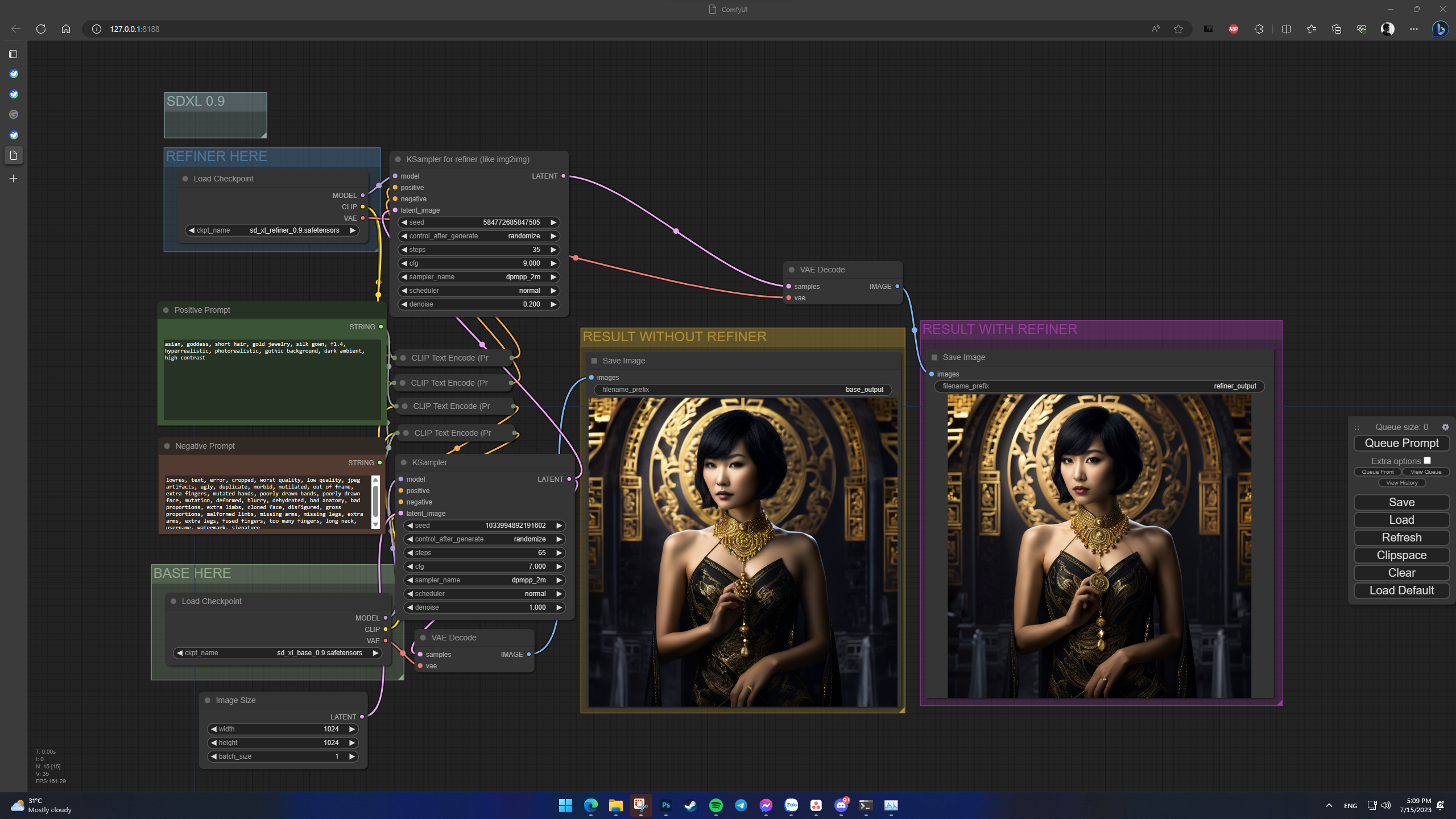

Workflow ComfyUI SDXL 0.9 - Pastebin.com
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
pastebin.com
Vận hành đòi cấu hình máy rất cao
Rất dễ nhận ra hai vấn đề với việc xử lý tạo hình bằng SD XL, cho dù là trên ComfyUI hay là Automatic1111 WebUI. Thứ nhất là tốc độ xử lý, bất chấp lựa chọn sampler là gì, cũng chỉ loanh quanh 4 đến 5 it/s, thay vì 15 đến 18 it/s khi xử lý tạo hình với SD 1.5. Và thứ hai, yêu cầu cấu hình khi làm việc với SD XL, chí ít là với phiên bản 0.9 là không hề thấp chút nào.

Ở phiên bản hiện tại, vì mức độ tối ưu, anh em dùng card đồ họa với dung lượng VRAM dưới 12GB (RTX 3080 Ti trở xuống) sẽ gặp rất nhiều khó khăn trong việc tạo hình bằng SD XL. Điều này chắc chắn sẽ được cải thiện trong những phiên bản nâng cấp sau này của mô hình diffusion từ Stability AI. Và như đã nói, bài này chỉ có giá trị mô tả những khác biệt trong hình ảnh mà SD XL tạo ra, so sánh với những mô hình cũ mà Stability AI nghiên cứu trong vòng hai năm trở lại đây.

Nếu chỉ xét giá trị của SD XL theo mục tiêu của bài viết, thì phải thừa nhận là mô hình này đang có rất nhiều tiềm năng. Mọi phong cách, từ nhiếp ảnh, hoạt hình, mô hình 3D hay mô phỏng những bộ phim hoạt hình của Pixar, SD XL đều làm tốt nhiệm vụ của nó.

Quan trọng nhất là, so với SD 1.5 và 2.1 mình từng trải nghiệm cách đây vài tháng, SD XL làm rất xuất sắc hai khía cạnh: Thứ nhất là khẩu độ bức hình theo lệnh input, và thứ hai là chi tiết bàn tay con người, trông đã tự nhiên hơn nhiều. Dù bàn tay vẫn chưa thực sự hoàn hảo, hay chí ít là tiệm cận những gì Midjourney có thể làm được, nhưng cải thiện so với những phiên bản Stable Diffusion cũ là rất đáng nhắc đến, và cũng là điểm đáng khen.

Đương nhiên vẫn có những lúc bàn tay trông rất quái dị, nhưng phần lớn thời gian, bàn tay của nhân vật trong tấm hình AI tạo ra trông rất thuyết phục.

Có một điểm rất dễ nhận ra với SD XL. Nếu tạo ra những bức hình với từ khóa “chân thực” hay “nhiếp ảnh”, chất lượng da dẻ của nhân vật trong những tấm hình, hoặc chất lượng ánh sáng đánh vào từng bộ phận trên cơ thể đều rất chi tiết. Điều này mô tả tần số mẫu mà thư viện hình ảnh Stability AI sử dụng để huấn luyện SD XL là rất đồ sộ. Tương tự như vậy là chất lượng bề mặt trang phục, sợi vải nhìn rất chi tiết, không bị bết và phẳng lì như trước đây.

Nếu anh em muốn nghịch thử ComfyUI với SD XL 0.9, một lời khuyên cho anh em là ở ô tùy chỉnh lệnh của model refiner, ở mục CFG, hãy chỉnh số lên cao một chút, ví dụ 8 hoặc 9, thậm chí hơn. Lúc này mô hình refiner sẽ không can thiệp chỉnh sửa quá nhiều so với tấm hình gốc, từ đó cho phép kết quả tạo hình trông trùng khớp hơn, thay vì hai mô hình tạo ra hai bức ảnh giống nhau về màu sắc bố cục, nhưng chi tiết lại rất khác biệt:
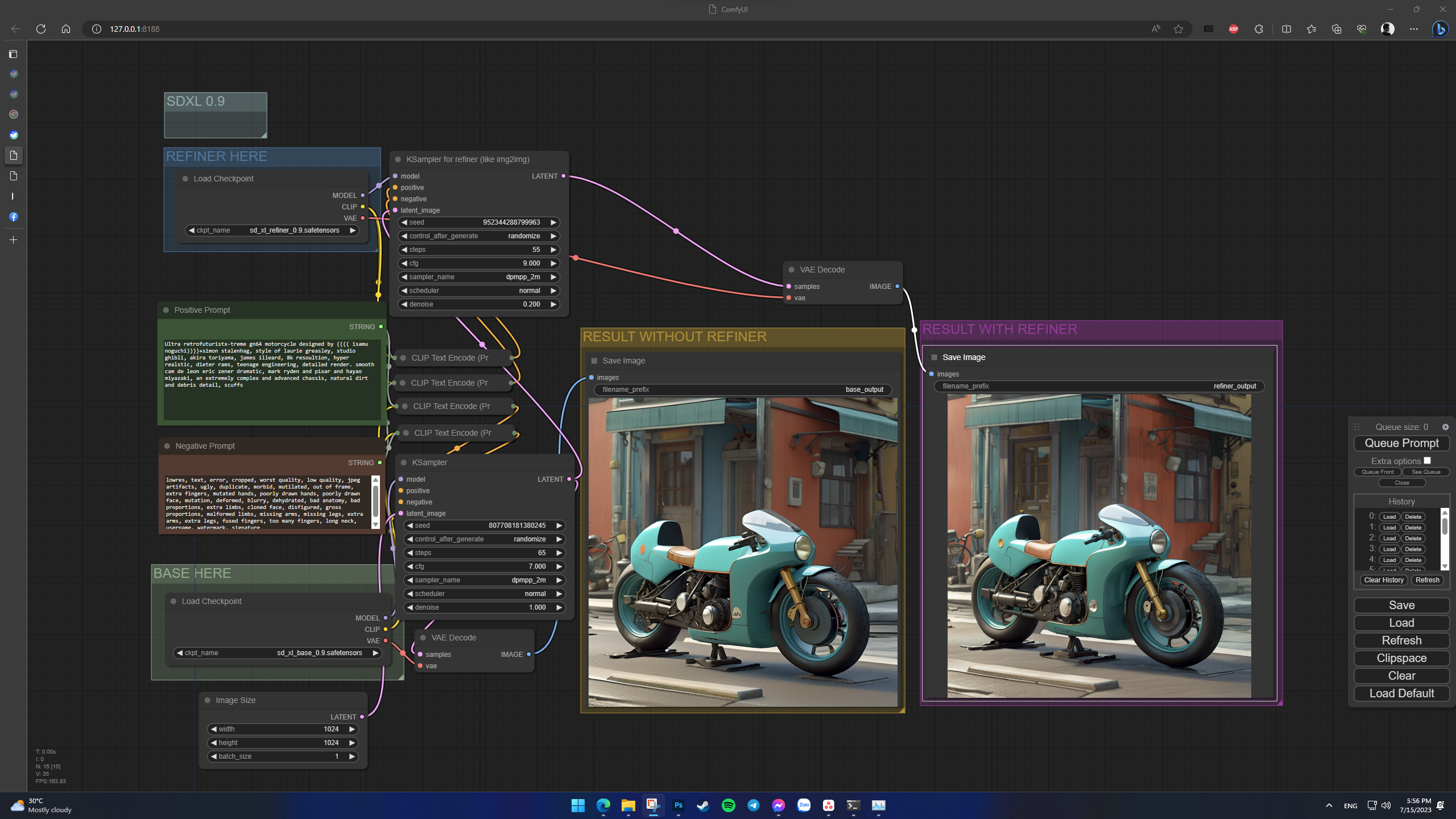

Và vấn đề cố hữu của những thuật toán diffusion tạo hình ảnh dựa trên những gì nó đã tự học được vẫn tồn tại, đó là chữ nghĩa trông vẫn kỳ quái, đúng kiểu AI hiểu ký tự như thế nào thì sẽ thể hiện y hệt như thế, không thể đọc được. Đương nhiên điều này không làm khó được những người tạo hình AI, vì không có gì Photoshop không làm được cả.

Mới chỉ là phiên bản 0.9, chưa phải bản chính thức, cũng chưa hoàn thiện 100%, mà SD XL đã có sức mạnh như thế này, chỉ cần VAE gốc và mô hình gốc cũng tạo ra được rất nhiều hình ảnh đa dạng, thoải mái chiều chuộng vô vàn ý tưởng của mọi người.
Để tạm kết bài trải nghiệm, mình cũng biết mong mỏi của rất nhiều anh em, đó là so sánh SD XL với sức mạnh của Firefly bên Adobe, công cụ inpainting và outpainting dựa trên thuật toán AI đang được ứng dụng vào Photoshop. Phải tới khi có những công cụ inpaint và outpaint dựa trên sức mạnh của SD XL, hỗ trợ những công cụ local như WebUI hay ComfyUI, thì chúng ta mới so sánh được giữa SD XL và Firefly. Nhưng mình cũng khá chắc là ngày đó sẽ tới rất sớm thôi, cùng lắm chỉ vài tuần kể từ khi SD XL chính thức phát hành phiên bản 1.0.


