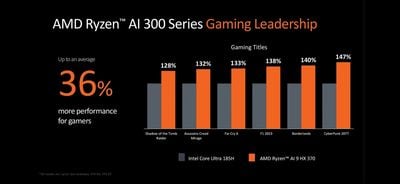
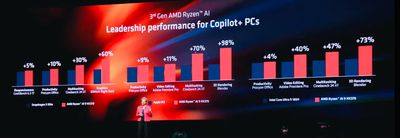
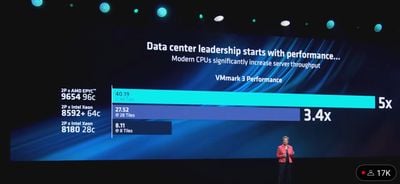
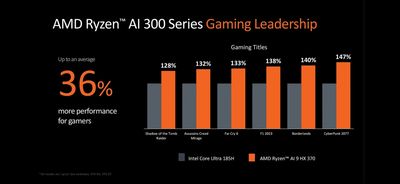
Bên cạnh Xeon 6 và Gaudi 3, sự kiện Computex cũng là dịp để Intel "khoe" kiến trúc Lunar Lake (LNL) với toàn bộ giới công nghệ, nhất là trên PC.
AI có thể nói đang là "hot trend" của công nghệ. Thế nên dù chỉ là một trong số rất nhiều tính năng, các công ty vẫn xem đây là điểm nhấn chính khi giới thiệu các sản phẩm mới trong năm này. Hãng chip x86 lớn nhất thế giới, hiển nhiên, cũng không bỏ qua điều này. Kiến trúc LNL hứa hẹn mang đến năng lực xử lý AI tới gần 120 TOPS trong một cấu hình hết sức nhỏ gọn và tiết kiệm điện.
Nhưng trước khi nói về AI của LNL, chúng ta hãy điểm sơ tổng quan con chip x86 mới này.
Nếu có theo dõi các thông tin gần đây về LNL, hẳn bạn cũng biết rằng con chip này mang một thiết kế đặc biệt tích hợp sẵn 2 khối DRAM có tổng dung lượng 32 GB trên cùng PCB. Cách làm này có 2 lợi điểm. (1) Hãng sản xuất laptop không cần phải trang bị thêm DRAM cho cỗ máy (tất nhiên họ vẫn có thể nếu muốn). (2) Tiết kiệm không gian PCB, giảm bớt số lớp mạch in dành cho khe RAM, đồng thời giảm bớt lượng điện tiêu thụ (hao tổn do chạy qua mạch in kéo dài).
AI có thể nói đang là "hot trend" của công nghệ. Thế nên dù chỉ là một trong số rất nhiều tính năng, các công ty vẫn xem đây là điểm nhấn chính khi giới thiệu các sản phẩm mới trong năm này. Hãng chip x86 lớn nhất thế giới, hiển nhiên, cũng không bỏ qua điều này. Kiến trúc LNL hứa hẹn mang đến năng lực xử lý AI tới gần 120 TOPS trong một cấu hình hết sức nhỏ gọn và tiết kiệm điện.
Nhưng trước khi nói về AI của LNL, chúng ta hãy điểm sơ tổng quan con chip x86 mới này.
RAM kèm sẵn, thiết kế siêu gọn
Nếu có theo dõi các thông tin gần đây về LNL, hẳn bạn cũng biết rằng con chip này mang một thiết kế đặc biệt tích hợp sẵn 2 khối DRAM có tổng dung lượng 32 GB trên cùng PCB. Cách làm này có 2 lợi điểm. (1) Hãng sản xuất laptop không cần phải trang bị thêm DRAM cho cỗ máy (tất nhiên họ vẫn có thể nếu muốn). (2) Tiết kiệm không gian PCB, giảm bớt số lớp mạch in dành cho khe RAM, đồng thời giảm bớt lượng điện tiêu thụ (hao tổn do chạy qua mạch in kéo dài).

Chip LNL kèm sẵn 32 GB bộ nhớ RAM
Mặc dù điểm trừ là chi phí sản xuất LNL sẽ cao hơn các chip không kèm DRAM khác, song nhìn chung hãng sản xuất sẽ không cần mua thêm RAM từ công ty khác, nên tổng thể giá thành tới tay người dùng gần như không thay đổi. Nên cơ bản đây là điểm cộng mạnh về thiết kế cho LNL.
Theo so sánh của Intel, việc hàn sẵn chip DRAM lên cùng PCB giúp làm giảm 40% mức tiêu thụ điện cho mạch in, từ đó giúp kéo dài thời gian sử dụng pin hơn trước. Ngoài ra, nó cũng tiết kiệm tới 250 mm2 diện tích PCB (so với việc gắn khe RAM riêng).

Toàn bộ con chip rất nhỏ gọn
Để cho rõ ràng hơn, trong đợt này của Lunar Lake, các vi xử lý Intel sẽ cố định với những tùy chọn dung lượng bộ nhớ trong xây dựng sẵn. Điều này tức là OEM sẽ không thể tùy biến hay bổ sung thêm khả năng nâng cấp RAM. Intel cho rằng với phân khúc sản phẩm mà Lunar Lake hướng tới - ultrabook nhỏ gọn, mỏng nhẹ thì 32 GB là đã đủ đáp ứng. Tất nhiên câu chuyện vẫn còn bỏ ngỏ, có thể những thế hệ sau, Intel sẽ cho phép OEM tùy biến nhiều hơn, hoặc tùy chọn mở rộng. Cá nhân mình xài 1 laptop mỏng nhẹ cũng chưa thấy cần quá 32 GB RAM, vì nhu cầu di chuyển nhiều và tập trung vào sự linh hoạt, thời gian xài pin nên các ứng dụng cũng rất cơ bản, 16 GB RAM cũng đủ.
Ít chiplet hơn, tích hợp sâu hơn
Còn nhớ khi Meteor Lake (MTL) ra mắt, đấy là con chip đầu tiên đánh dấu việc Intel chuyển sang dùng thiết kế chiplet (hoặc MCM). Tại thời điểm đó, MTL được cấu tạo từ 4 chiplet riêng biệt gồm CPU, GPU, SoC và IO, tương đối "cồng kềnh". Nhưng sang LNL thì số lượng chiplet giảm xuống còn 3 (thực tế là 2), cụ thể chúng ta còn die compute (CPU, GPU, NPU), IO (PCH) và... die "làm đầy" (filler).

Quảng cáo
Các thành phần làm nên LNL
* Die filler là một trường hợp thú vị vì nó chả... tính toán gì cả! Nó tồn tại là vì die IO không rộng bằng die compute, dẫn tới việc khi đặt miếng tản nhiệt (IHS) lên có thể dẫn tới việc bị "kênh", khiến cho bề mặt tiếp xúc không tốt và tản nhiệt kém hiệu quả. Bạn có thể hình dung die filler như mấy miếng giấy hoặc ván gỗ kê dưới chân bàn cho nó không bị bập bênh là được! Thực tế die filler cũng có tác dụng phụ để hấp thụ bớt nhiệt từ các die khác (vì không hoạt động), nhưng vai trò chính vẫn là "miếng lót bàn" *
Vì thế theo cách nhìn khác, cấu trúc LNL chặt chẽ hơn MTL khi phần lớn dữ liệu không phải luân chuyển nhiều lần. Nếu tạm gác die IO qua một bên, LNL có thiết kế gần như là monolithic. Nhưng vì "co bóp" quá nhiều thành phần tính toán như vậy, nên điểm trừ của LNL là số nhân xử lý của nó không nhiều.
P-core Lion Cove & E-core Skymont
* Trong bài này chúng ta chỉ nắm sơ lược tổng quan kiến trúc LNL. Bài phân tích sâu hơn sẽ dành trong một dịp khác *

Kiến trúc Meteor Lake - Cuộc cách mạng chip lớn nhất 40 năm qua của Intel
2024 hứa hẹn sẽ là một năm có nhiều cuộc cạnh tranh dữ dội trong mảng chip máy tính. Cụ thể nhất sẽ là kiến trúc Zen 5 của AMD và Meteor Lake từ Intel.
Có thể nói cuộc sống ngày nay của chúng ta đã thay đổi rất nhiều so với vài chục năm trước…
tinhte.vn

Phân tích kỹ thuật nhân CPU trên Intel Meteor Lake - Không dành cho Windows 10?
Dù Meteor Lake (MTL) là một chip đa thành phần (SoC), thì sức mạnh CPU vẫn là "linh hồn" của một hệ thống PC. Ở bài viết này, chúng ta sẽ phân tích sâu hơn kiến trúc P-Core Redwood Cove và E-Core Crestmont nằm trên con chip mới nhất của Intel…
tinhte.vn
Quảng cáo

Phân tích kỹ thuật nhân CPU trên Intel Meteor Lake - E-core và Hybrid Architect
Với phần trước chúng ta đã nói về kiến trúc nhân P-core Redwood Cove của Meteor Lake (MTL). Ở phần này, cấu trúc nhân E-core Crestmont cũng như năng lực xử lý của cụm SoC sẽ là chủ điểm.
https://tinhte.
tinhte.vn
Về cơ bản, cả Lion Cove và Skymont đều là bản nâng cấp "mạnh" từ Redwood Cove và Crestmont. Và nếu không muốn nói là "cực mạnh" so với các thế hệ trước đó.

Cấu trúc nhân P-core Lion Cove
Với Lion Cove, nhân xử lý này đã mở rộng lên 8-wide decoder lẫn 8-wide allocation. Trong khi Redwood Cove là 6-wide còn các thế hệ 14 nm chỉ mới là 4-wide. Để tiện so sánh thì phía AMD Zen 4 trở về trước cũng chỉ là 4-wide. Đây là lý do tại sao Intel thường có hiệu năng đơn luồng cao hơn AMD. Và nhìn chung trong thế giới chip, các thiết kế ARM gần đây nhất là từ Apple cũng có hiệu năng rất cao nhờ sự mở rộng kiến trúc xử lý này.
Ngoài ra không chỉ mở rộng front-end. Phần execution và back-end của LNL cũng được tăng cường hơn với 4 pipeline FPU, 6 ALU và 6 AGU, L2 Cache được tăng lên đến 3 MB. Về mặt hiệu năng, Intel cho biết Lion Cove có IPC cao hơn Redwood Cove tới 14%.

Cấu trúc nhân E-core Skymont
Sang Skymont, điểm gây bất ngờ là nó được nâng cấp tới 3 bộ decoder (3-wide mỗi bộ). Ở Crestmont chỉ có 2 decoder (cũng 3-wide). Nhưng có lẽ vì là E-core nên phần allocation chỉ dừng ở mức 8-wide thay vì 9-wide cho tương xứng với 3x 3 decoder ở trên. Và điều này có nghĩa Skymont về cơ bản cũng 8-wide tương đương với Lion Cove. Song phần execution và back-end không có nhiều thay đổi, ngoại trừ số pipeline FPU nhiều hơn so với Crestmont. Cả 4 nhân Skymont vẫn "chia chung" 4 MB L2 Cache y hệt như thế hệ mới.
Song một chi tiết nổi bật nhất là LNL giờ đây không còn Low Power Island (LP-E) như MTL nữa. Cá nhân mình cho đây là quyết định đúng đắn vì thực tế chỉ 2 lớp nhân xử lý thôi cũng đã tạo ra bao nhiêu vấn đề cho OS "hiểu" và xử lý. Tăng thêm tới 3 lớp nhân xử lý thật sự là... rách việc! Đấy là chưa kể tới việc không có nhiều người "thích" E-core cho lắm.

LNL chỉ có 2 cụm nhân P-core và E-core
Thread Director (TD) mới - Lý do không còn SMT?
Kể từ khi ra kiến trúc hybrid, Intel đã kèm thêm một công cụ quản lý mới là TD. Công cụ này có vai trò làm "thông dịch viên" giữa OS và các nhân xử lý. Ở các kiến trúc trước, vốn chỉ có 1 loại nhân xử lý, OS hoàn toàn có thể phân chia thoải mái công việc cho mọi nhân rất dễ dàng. Nhưng khi chia ra P-core và E-core, hoạt động này trở nên phức tạp hơn, nên buộc cần có một bộ quản lý đệm để "hiểu" việc nào "nặng", việc nào "nhẹ" mà chọn nhân xử lý cho phù hợp.


Cách phân chia công việc trên LNL
Về cơ bản, TD của LNL "kế thừa" tiếp cách làm việc trên MTL - ưu tiên E-core trước rồi mới tới P-core. Nhưng vì không còn LP-E nữa, TD sẽ làm việc dễ chịu hơn khi chỉ còn 2 tầng chip khác nhau. Song điểm đáng chú ý là 1 thread E-core sẽ ứng với 1 thread P-core và ngược lại. Mà E-core không có năng lực SMT, nó dẫn tới việc khi đưa công việc của E-core lên P-core thì P-core cũng chỉ chạy được 1 thread duy nhất. Kết quả là dù LNL có 8 nhân nhưng nó cũng chỉ xử lý được 8 luồng dữ liệu (4 mạnh + 4 yếu). Và tuy LNL chỉ dùng cho laptop tiết kiệm điện, thì việc chỉ có tối đa 4 P-core cũng đặt ra nhiều câu hỏi về mặt hiệu năng. Nhưng cứ phải chờ tới khi có sản phẩm chính thức chúng ta mới rõ vấn đề này được.
GPU Xe2 thế hệ mới
Có thể nói khôi hài một tý là nếu bỏ GPU ra khỏi LNL thì die compute sẽ rộng bằng die IO và chúng ta chẳng cần tới die filler nữa. Vì phần thừa ra trên die compute chính là GPU Xe2 (Battlemage) của con chip!

GPU LNL mạnh gấp 1.5 lần MTL
Về cơ bản, LNL cũng vẫn có 8 nhân Xe (Alchemist) tương tự như MTL. Tuy vậy ở góc độ sâu hơn, nhân Xe2 khác Xe khá nhiều. 16 engine vector (XVE) và 16 engine matrix (XMX) trên 1 nhân Alchemist được gom lại còn 8 engine vector và 8 engine matrix trên 1 nhân Battlemage. Bù lại thì giao tiếp các engine này tăng gấp đôi so với thế hệ trước (256 vs. 512 bit và 1024 vs. 2048 bit).
Song điểm thay đổi nhiều nhất có lẽ ra bộ máy ray tracing (RTU). Nếu ở Alchemist mỗi RTU chỉ có 2 Traversal pipeline thì trên Battlemage con số này là 3. Ngoài ra, như bạn cũng có thể đã biết, Intel mới bắt đầu làm GPU sau hơn 2 thập kỷ không đụng tới. Thế hệ Intel Arc đầu tiên xem như là những bước chập chững đầu đời. Vì vậy kinh nghiệm tối ưu card đồ hoạ với Intel gần như là số không. Chính CEO Intel cũng thừa nhận Alchemist bị chậm ra mắt vì driver chưa được tối ưu (và kể cả đã ra mắt rồi vẫn đầy bug).

Cấu tạo engine vector của Xe2
Đến Battlemage, Intel "biến đau thương thành sức mạnh", tối ưu lại các dòng lệnh để tiến độ xử lý công việc trôi chảy hơn. Hãng cố gắng phân phối đầu việc tới từng nhân Xe hiệu quả hơn, giảm ảnh hưởng từ code phần mềm lại. Công ty này cho 8 nhân Xe2 của LNL có hiệu năng gấp 1,5 lần 8 nhân Xe của MTL. Và nếu "bắc cầu" MTL mạnh đồ hoạ gấp đôi nhân Iris X trên dòng chip Alder Lake thì LNL là mạnh gấp 3 lần con số đó.
NPU4, đủ mạnh để làm Copilot
Mặc dù Intel quảng cáo LNL có năng lực AI lên đến 120 TOPS, nhưng đó là con số tổng của cả CPU, GPU và NPU. Và nếu tinh ý, bạn có thể thấy hơn 1/2 sức mạnh đó đến từ 8 nhân GPU Xe2. Như vậy nếu trừ phần của GPU ra thì CPU + NPU LNL chỉ nhỉnh hơn 50 TOPS. Thực tế là toàn 8 nhân P-core và E-core chỉ đạt được có 5 TOPS. Cụ thể thì NPU4 đạt 48 TOPS, xem như là "vừa đủ" để đạt yêu cầu Copilot của Microsoft (40 TOPS) và ngang ngửa Snapdragon X Elite lẫn Zen 5.

Tổng sức mạnh AI của LNL đạt gần 120 TOPS
Dĩ nhiên so với MTL hay Zen 4, NPU4 mạnh hơn rất nhiều. Cả 2 đại diện trước chỉ có sức mạnh từ 10 ~ 16 TOPS, xem như có thể trải nghiệm sơ sơ AI chứ để xài mượt mà thì chưa tới. Và nếu để so sánh, tỷ lệ diện tích NPU trên LNL cao hơn nhiều so với MTL (NPU nằm trong die IO), cho thấy sự gia tăng đáng kể năng lực xử lý. Cụ thể NPU4 có tới 6 engine neural (MTL chỉ có 2 engine). Và mỗi engine neural LNL lại có 2 bộ Shaved DSP (trên MTL chỉ có 1 DSP). Chính khác biệt cơ bản này giúp cho NPU của LNL có sức mạnh gấp 5 lần thế hệ cũ.


Vị trí NPU và cấu tạo của nó trên LNL
Die IO, hoàn chỉnh cho một SoC
Dù là thành phần không nhận được nhiều tràng pháo tay hay ánh đèn sân khấu, các kết nối IO vẫn đóng một vai trò quan trọng để giúp các nhân điện toán "liên lạc" với thế giới bên ngoài. Về cơ bản trong kỷ nguyên IoT, không có Internet thì bạn gần như bị cô lập trên "hoang đảo".

LNL được trang bị những liên kết mới nhất
Vì vậy đến LNL, bạn sẽ những liên kết mới nhất hiện nay như Wi-Fi 7 (5 Gig), Bluetooth 5.4, 3 liên kết Thunderbolt 4 kết hợp tính năng Thunderbolt Share cho phép bạn trao đổi dữ liệu giữa các PC cùng có giao tiếp Thunderbolt. Tất nhiên không thể bỏ qua liên kết 4 lane PCIe 4.0 và 4 lane PCIe 5.0 để gắn những ổ SSD mới nhất, cùng các cổng USB 2.0 & 3.0 cho các thiết bị ngoại vi.
Trên đây là những gì tổng quan về LNL. Chúng ta sẽ phân tích chi tiết hơn kiến trúc ở những bài sâu hơn.