
Tuần này, Intel tổ chức sự kiện Vision 2024 tại Phoenix, Arizona, nơi họ giới thiệu những thông tin đầu tiên về kiến trúc chip xử lý AI Gaudi 3, hiện được công ty con thuộc Intel, Havana Labs nghiên cứu phát triển.
Trước đó, Intel đã khoe về sức mạnh của Gaudi 2, hiệu năng tiệm cận rất gần với Nvidia H100, một trong những lựa chọn hàng đầu về hiệu năng huấn luyện cũng như vận hành LLM phục vụ các doanh nghiệp và tập đoàn công nghệ. Còn với Gaudi 3, Intel tự tin nói rằng, hiệu năng của con chip xử lý AI này đủ sức vượt qua H100 trong tác vụ vận hành những mô hình ngôn ngữ, nền tảng của những chatbot và dịch vụ AI phổ biến hiện nay. Nhưng thời điểm Gaudi 3 ra mắt cũng sẽ là lúc Nvidia giao những con chip khổng lồ B200 kiến trúc Blackwell cho các đối tác và khách hàng.


Trước đó, Intel đã khoe về sức mạnh của Gaudi 2, hiệu năng tiệm cận rất gần với Nvidia H100, một trong những lựa chọn hàng đầu về hiệu năng huấn luyện cũng như vận hành LLM phục vụ các doanh nghiệp và tập đoàn công nghệ. Còn với Gaudi 3, Intel tự tin nói rằng, hiệu năng của con chip xử lý AI này đủ sức vượt qua H100 trong tác vụ vận hành những mô hình ngôn ngữ, nền tảng của những chatbot và dịch vụ AI phổ biến hiện nay. Nhưng thời điểm Gaudi 3 ra mắt cũng sẽ là lúc Nvidia giao những con chip khổng lồ B200 kiến trúc Blackwell cho các đối tác và khách hàng.
Nvidia Blackwell B200: Chip AI mạnh nhất thế giới, mạnh hơn H200 từ 2.5 đến 5 lần, thiết kế chiplet
GTC 2024, sự kiện công bố những sản phẩm phần cứng và phần mềm mới của Nvidia đã khai mạc, và trung tâm của sự kiện, và được trông đợi nhất có lẽ là kiến trúc chip GPGPU (general purpose graphics processing unit) mới của Nvidia, tên mã Blackwell…
tinhte.vn
Google Axion: Chip xử lý AI cho data center, kiến trúc ARM
Google Cloud vừa công bố một chip xử lý kiến trúc ARM mới, đặt tên là Axion. Con chip xử lý phục vụ riêng nhu cầu vận hành những dịch vụ AI này sẽ chỉ hiện diện trong những data center lớn vận hành tính năng AI trên đám mây…
tinhte.vn
Chi tiết kiến trúc
Kiến trúc của Gaudi 3 gần như giống hệt như Gaudi 2 vể kết cấu transistor và cách những cụm nhân xử lý tensor và ma trận được triển khai trên bề mặt die.
Nhưng có thể đưa ra những so sánh về mặt kết cấu giữa Intel Gaudi 3 và Nvidia B200. B200 là hai die GPU kết hợp lại với nhau thông qua cầu nối interconnect, vì giới hạn 800mm2 mỗi die silicon dạng monolithic mà thiết bị gia công bán dẫn hiện hành của các fab có thể làm được. Tương tự như vậy, Intel ghép hai die chip xử lý lại với nhau bằng cầu interconnect băng thông cao để tạo ra Gaudi 3.
Mỗi cụm nhân xử lý AI trên Gaudi 3 trang bị 48 MB bộ nhớ đệm nằm ở vị trí trung tâm. Xung quanh cụm bộ nhớ đệm là 4 matrix engine và 32 cụm nhân tensor. Rồi nếu anh em nhìn vào tấm hình cover, 8 die RAM băng thông cao đặt ngay sát cụm nhân xử lý AI, kết hợp với những cụm nhân xử lý hạ tầng mạng hay xử lý media trên bề mặt con chip silicon.
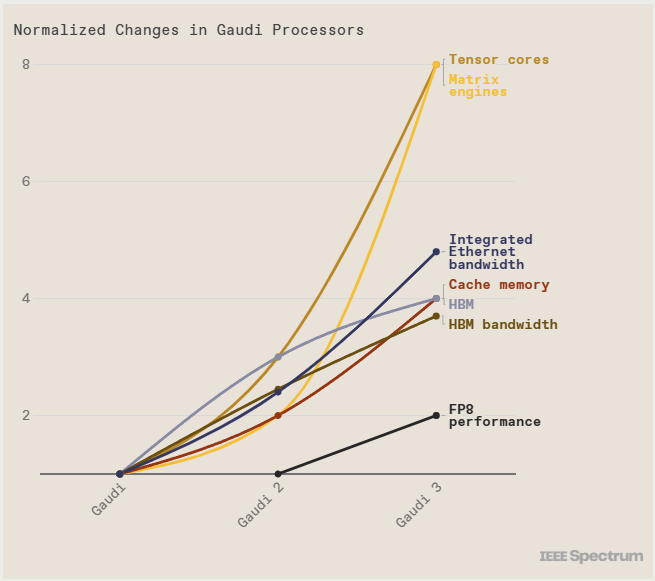
Intel cho biết, với những bài thử nghiệm xử lý số thực dấu phẩy động 8-bit, Gaudi 3 có sức mạnh xử lý AI gấp đôi so với thế hệ chip trước. INT8 là mấu chốt của quá trình huấn luyện những mô hình transformer. Còn với số thực dấu phẩy động BFloat 16, hiệu năng của Gaudi 3 tăng gấp 4 lần so với Gaudi 2.
Intel Gaudi 3 vs Nvidia H100
Tại sự kiện Vision 2024, Intel đưa ra dự báo rằng, so sánh với H100, tốc độ huấn luyện mô hình với 175 tỷ tham số như GPT-3 của Gaudi 3 sẽ nhanh hơn 40%. Những mô hình từ 7 đến 8 tỷ tham số như những phiên bản LLaMa 2 của Meta thậm chí sẽ còn tạo ra chênh lệch hiệu năng lớn hơn, rút ngắn thời gian huấn luyện mô hình ngôn ngữ.
Còn về hiệu năng nội suy dữ liệu từ mô hình ngôn ngữ, nói cách khác là quá trình vận hành mô hình ngôn ngữ trong những ứng dụng thương mại, chênh lệch hiệu năng có phần sát sao hơn. Chẳng hạn như với hai phiên bản mô hình LLaMa của Meta, Gaudi 3 tạo ra hiệu năng tương đương 95 đến 170% so với H100 của Nvidia. Với mô hình Falcon 180B, 180 tỷ tham số, huấn luyện dựa trên 3.5 nghìn tỷ token, có lúc Gaudi 3 tạo ra hiệu năng nội suy văn bản nhanh gấp 4 lần so với H100.
Nếu so sánh với H200, sức mạnh của Gaudi 3 dao động từ 80 đến 110% hiệu năng H100 với LLaMa, và vận hành Falcon 180B nhanh hơn 3.8 lần.
Quảng cáo
Cùng lúc, Intel cũng đề cập tới tiết kiệm điện năng khi vận hành Gaudi 3 trong những data center. So sánh với H100, performance/watt của Gaudi 3 cao hơn H100 220% khi chạy mô hình LLaMa, 230% khi chạy mô hình Falcon.
Intel Gaudi 3 vs Nvidia B200
Hiện giờ cả hai sản phẩm này đều chưa được ra mắt chính thức, chưa được ứng dụng vận hành trong những data center chạy những dịch vụ AI phục vụ cho hàng chục, hàng trăm triệu người trên toàn thế giới. Nhưng cũng có vài chi tiết thông số kỹ thuật có thể đem ra so sánh giữa Gaudi 3 và B200. Quan trọng nhất, là dung lượng và băng thông bộ nhớ HBM trên die chip xử lý AI.
Bên cạnh sức mạnh xử lý của những cụm nhân tensor và matrix, thì bộ nhớ cũng như dung lượng bộ nhớ luôn là thứ cực kỳ quan trọng với ngành nghiên cứu và vận hành AI. Khi những mô hình AI giờ hoạt động dựa trên hàng chục tỷ tham số về mặt quy mô và kích thước, thì hai khía cạnh này lại càng trở nên quan trọng.
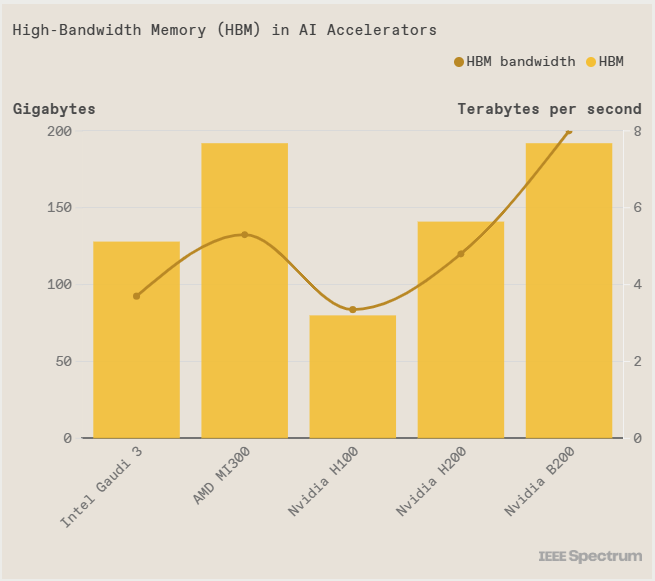
Cả Intel Gaudi 3 lẫn Nvidia B200 đều được trang bị những die RAM HBM, chồng những lớp DRAM lên trên bộ controller để cung cấp dữ liệu cho chip xử lý vận hành. Để những cụm HBM nằm chung với những nhân xử lý tensor và matrix trên những con chip xử lý AI, cần tới những công nghệ đóng gói chip cao cấp nhất hiện giờ, như cầu nối silicon EMIB của Intel, hay CoWoS của TSMC, tạo ra những cầu nối băng thông cao giữa bộ nhớ và chip logic.
Quảng cáo
Gaudi 3 có bộ nhớ cao hơn Nvidia H100, nhưng lại thua H200, B200 của Nvidia và Instinct MI300 của AMD. Việc sử dụng công nghệ chip nhớ HBM2e so với HBM3 như 4 sản phẩm được đem ra so sánh có thể sẽ tạo ra lợi thế cạnh tranh về giá mỗi con chip mà Intel bán cho các khách hàng.
Một yếu tố cần đề cập nữa, Gaudi 3 được gia công trên tiến trình N5 của TSMC chứ không phải Intel 7 hay Intel 4. Blackwell B200 thì được gia công trên tiến trình N4, phiên bản 5nm nâng cấp của TSMC thay vì N3, hiện tại đang được ứng dụng để gia công những chip xử lý tiêu dùng cho Apple, trang bị trong iPhone và máy tính Mac. Theo TSMC, N4P tạo ra hiệu năng cải thiện 11%, hiệu quả tiêu thụ điện tăng 22% và mật độ transistor tăng 6% so với N5.
Theo IEEE Spectrum
